
Просочившаяся записка Google предлагает пошаговое изложение того, почему Google проигрывает ИИ с открытым исходным кодом, и предлагает путь назад к доминированию и владению платформой.
Меморандум начинается с признания того, что их конкурент никогда не был OpenAI и всегда должен был быть с открытым исходным кодом.
Содержание
- 1 Не может конкурировать с открытым исходным кодом
- 2 Большой размер языковой модели не является преимуществом
- 3 Масштаб открытого исходного кода пугает Google
- 4 Открытый исходный код исторически превзошел закрытый исходный код
- 5 Процесс создания модели с открытым исходным кодом превосходен
- 6 Если вы не можете победить Open Source, присоединяйтесь к ним
Не может конкурировать с открытым исходным кодом
Кроме того, они признают, что никоим образом не способны конкурировать с открытым исходным кодом, признавая, что уже проиграли борьбу за доминирование ИИ.
Они написали:
«Мы много оглядывались в OpenAI. Кто преодолеет следующий рубеж? Каким будет следующий ход?
Но неприятная правда в том, что мы не в состоянии выиграть эту гонку вооружений, как и OpenAI. Пока мы ссорились, третья фракция спокойно ела наш обед.
Я говорю, конечно же, об открытом исходном коде.
Проще говоря, они нас обхаживают. То, что мы считаем «большими открытыми проблемами», сегодня решено и находится в руках людей».
Основная часть меморандума посвящена тому, как открытый исходный код проигрывает Google.
И хотя у Google есть небольшое преимущество перед открытым исходным кодом, автор меморандума признает, что оно ускользает и никогда не вернется.
Самоанализ метафорических карт, которые они сами раздали, весьма пессимистичен:
«Хотя наши модели все еще имеют небольшое преимущество в плане качества, разрыв сокращается поразительно быстро.
Модели с открытым исходным кодом более быстрые, более настраиваемые, более частные и более функциональные.
Они делают вещи с параметрами за 100 и 13 миллиардов долларов, с которыми мы боремся за 10 миллионов долларов и 540 миллиардов долларов.
И они делают это за недели, а не месяцы».
Большой размер языковой модели не является преимуществом
Возможно, самое пугающее осознание, выраженное в меморандуме, заключается в том, что размер Google больше не является преимуществом.
Невероятно большой размер их моделей теперь рассматривается как недостаток, а не как непреодолимое преимущество, которым они их считали.
В просочившейся записке перечисляется ряд событий, которые сигнализируют о том, что контроль Google (и OpenAI) над ИИ может быстро закончиться.
В нем говорится, что всего месяц назад, в марте 2023 года, сообщество открытого исходного кода получило утечку большой языковой модели с открытым исходным кодом, разработанную Meta, под названием LLaMA.
В течение нескольких дней и недель глобальное сообщество открытого исходного кода разработало все компоненты, необходимые для создания клонов Bard и ChatGPT.
Сложные шаги, такие как настройка инструкций и обучение с подкреплением на основе обратной связи с человеком (RLHF), были быстро воспроизведены глобальным сообществом открытого исходного кода, причем по дешевке.
- Инструкция по настройке
Процесс тонкой настройки языковой модели, чтобы заставить ее делать что-то конкретное, для чего она изначально не была обучена. - Обучение с подкреплением на основе обратной связи с человеком (RLHF)
Техника, при которой люди оценивают выходные данные языковых моделей, чтобы узнать, какие выходные данные удовлетворяют людей.
RLHF — это метод, используемый OpenAI для создания InstructGPT, который является моделью, лежащей в основе ChatGPT, и позволяет моделям GPT-3.5 и GPT-4 получать инструкции и выполнять задачи.
RLHF — это огонь, который открытый исходный код взял из
Масштаб открытого исходного кода пугает Google
Что особенно пугает Google, так это тот факт, что движение за открытый исходный код может масштабировать свои проекты так, как закрытый исходный код не может.
Набор данных вопросов и ответов, используемый для создания клона ChatGPT с открытым исходным кодом, Dolly 2.0, был полностью создан тысячами сотрудников-добровольцев.
Google и OpenAI частично полагались на вопросы и ответы, полученные с таких сайтов, как Reddit.
Утверждается, что набор данных вопросов и ответов с открытым исходным кодом, созданный Databricks, имеет более высокое качество, потому что люди, которые внесли свой вклад в его создание, были профессионалами, а их ответы были длиннее и содержательнее, чем то, что можно найти в типичном наборе данных вопросов и ответов, извлеченном из общественный форум.
В просочившейся записке говорилось:
«В начале марта сообщество открытого исходного кода получило в свои руки свою первую действительно мощную модель фундамента, когда LLaMA от Meta просочилась в открытый доступ.
У него не было инструкций или настройки разговора, а также RLHF.
Тем не менее, сообщество сразу же поняло значение того, что им было дано.
За этим последовало огромное излияние инноваций, и между крупными разработками оставалось всего несколько дней…
Вот и мы, всего месяц спустя, и есть варианты с настройкой инструкций, квантованием, улучшением качества, человеческими оценками, мультимодальностью, RLHF и т. д. и т. д., многие из которых основаны друг на друге.
Самое главное, они решили проблему масштабирования до такой степени, что каждый может повозиться.
Многие из новых идей исходят от обычных людей.
Входной барьер для обучения и экспериментов снизился с общей производительности крупной исследовательской организации до одного человека, вечера и мощного ноутбука».
Другими словами, то, на что у Google и OpenAI ушли месяцы и годы обучения и создания, у сообщества открытого исходного кода заняло всего несколько дней.
Это должно быть действительно пугающим сценарием для Google.
Это одна из причин, по которой я так много пишу о движении ИИ с открытым исходным кодом, потому что действительно похоже, каким будет будущее генеративного ИИ в относительно короткий период времени.
Открытый исходный код исторически превзошел закрытый исходный код
В служебной записке упоминается недавний опыт работы с DALL-E от OpenAI, моделью глубокого обучения, используемой для создания изображений, по сравнению со стабильной диффузией с открытым исходным кодом, как предвестником того, что в настоящее время происходит с генеративным ИИ, таким как Bard и ChatGPT.
Dall-e был выпущен OpenAI в январе 2021 года. Stable Diffusion, версия с открытым исходным кодом, была выпущена полтора года спустя, в августе 2022 года, и за несколько коротких недель обогнала по популярности Dall-E.
Этот временной график показывает, как быстро Stable Diffusion обогнала Dall-E:
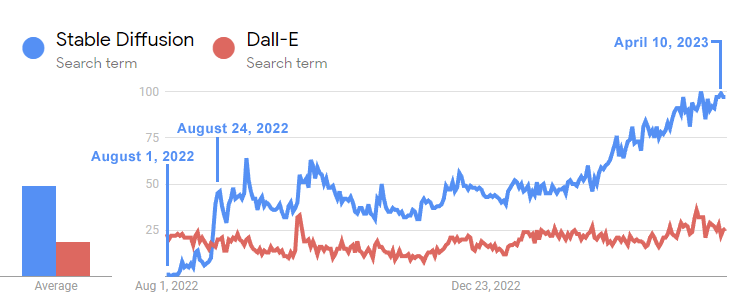
Приведенная выше временная шкала Google Trends показывает, как интерес к модели Stable Diffusion с открытым исходным кодом значительно превысил интерес к Dall-E в течение трех недель после ее выпуска.
И хотя Dall-E отсутствовал полтора года, интерес к Stable Diffusion продолжал расти в геометрической прогрессии, в то время как Dall-E от OpenAI оставался на прежнем уровне.
Экзистенциальная угроза подобных событий, настигающих Барда (и OpenAI), вызывает у Google кошмары.
Процесс создания модели с открытым исходным кодом превосходен
Еще один фактор, который беспокоит инженеров Google, заключается в том, что процесс создания и улучшения моделей с открытым исходным кодом является быстрым, недорогим и идеально подходит для глобального совместного подхода, характерного для проектов с открытым исходным кодом.
В служебной записке отмечается, что новые методы, такие как LoRA (низкоранговая адаптация больших языковых моделей), позволяют точно настроить языковые модели в течение нескольких дней с чрезвычайно низкими затратами, при этом окончательный LLM сопоставим с чрезвычайно более дорогими LLM. созданный Google и OpenAI.
Еще одно преимущество заключается в том, что инженеры с открытым исходным кодом могут опираться на предыдущую работу, повторять итерации вместо того, чтобы начинать с нуля.
Сегодня нет необходимости создавать большие языковые модели с миллиардами параметров, как это делают OpenAI и Google.
Возможно, именно на это недавно намекал Сэм Алтон, когда недавно сказал, что эра массивных больших языковых моделей закончилась.
Автор меморандума Google сравнил дешевый и быстрый подход LoRA к созданию LLM с нынешним подходом к большому ИИ.
Автор меморандума размышляет о недостатках Google:
«Напротив, обучение гигантских моделей с нуля не только отбрасывает предварительное обучение, но и любые итерационные улучшения, которые были сделаны сверху. В мире с открытым исходным кодом не требуется много времени, чтобы эти улучшения стали доминировать, что делает полное переобучение чрезвычайно дорогостоящим.
Мы должны задуматься над тем, действительно ли для каждого нового приложения или идеи нужна совершенно новая модель.
…Действительно, с точки зрения инженерно-часов, темпы улучшения этих моделей значительно опережают то, что мы можем сделать с нашими самыми большими вариантами, а лучшие уже в значительной степени неотличимы от ChatGPT».
Автор приходит к выводу, что то, что они считали своим преимуществом, их гигантскими моделями и сопутствующей непомерно высокой стоимостью, на самом деле было недостатком.
Глобальная совместная природа открытого исходного кода более эффективна и на порядки быстрее в инновациях.
Как система с закрытым исходным кодом может конкурировать с огромным количеством инженеров по всему миру?
Автор приходит к выводу, что они не могут конкурировать и что прямая конкуренция, по их словам, «проигрышна».
Это кризис, буря, которая развивается за пределами Google.
Если вы не можете победить Open Source, присоединяйтесь к ним
Единственное утешение, которое автор меморандума находит в открытом исходном коде, заключается в том, что, поскольку инновации в открытом исходном коде бесплатны, Google также может воспользоваться ими.
Наконец, автор приходит к выводу, что единственный доступный для Google подход — это владеть платформой так же, как они доминируют над платформами Chrome и Android с открытым исходным кодом.
Они указывают на то, что Meta получает выгоду от выпуска своей большой языковой модели LLaMA для исследований, и как теперь тысячи людей делают свою работу бесплатно.
Возможно, главный вывод из меморандума заключается в том, что Google может в ближайшем будущем попытаться воспроизвести свое доминирование в области открытого исходного кода, выпустив свои проекты на основе открытого исходного кода и тем самым завладеть платформой.
В служебной записке делается вывод, что переход на открытый исходный код является наиболее жизнеспособным вариантом:
«Google должен заявить о себе как о лидере в сообществе открытого исходного кода, взяв на себя инициативу, сотрудничая с более широким диалогом, а не игнорируя его.
Это, вероятно, означает принятие некоторых неудобных шагов, таких как публикация весов моделей для небольших вариантов ULM. Это обязательно означает отказ от некоторого контроля над нашими моделями.
Но этот компромисс неизбежен.
Мы не можем надеяться одновременно стимулировать инновации и контролировать их».
Открытый исходный код уходит с огнем ИИ
На прошлой неделе я упомянул греческий миф о человеческом герое Прометее, крадущем огонь у богов на горе Олимп, противопоставив открытый исходный код Прометею «олимпийским богам» Google и OpenAI:
я твитнул:
«В то время как Google, Microsoft и Open AI ссорятся друг с другом и отвернулись друг от друга, Open Source уходит со своим огнем?»
Утечка меморандума Google подтверждает это наблюдение, но также указывает на возможное изменение стратегии Google, чтобы присоединиться к движению открытого исходного кода и, таким образом, кооптировать его и доминировать над ним так же, как они сделали с Chrome и Android.
Прочтите просочившуюся заметку Google здесь:
