
В недавнем посте на LinkedIn аналитик Google Гэри Иллис освещает малоизвестные аспекты файла robots.txt, отмечающего свое 30-летие.
Файл robots.txt, компонент сканирования и индексирования веб-страниц, с момента своего появления стал основой SEO-практики.
Вот одна из причин, почему он остается полезным.
Содержание
Надежная обработка ошибок
Иллис подчеркнул устойчивость файла к ошибкам.
«robots.txt практически не содержит ошибок», Ильес заявил.
В своем посте он объяснил, что парсеры robots.txt разработаны таким образом, чтобы игнорировать большинство ошибок без ущерба для функциональности.
Это означает, что файл продолжит работу, даже если вы случайно включите не относящийся к нему контент или неправильно напишете директивы.
Он пояснил, что синтаксические анализаторы обычно распознают и обрабатывают ключевые директивы, такие как user-agent, allow и disallow, игнорируя при этом нераспознанный контент.
Неожиданная функция: линейные команды
Иллис указал на наличие строчных комментариев в файлах robots.txt, что показалось ему странным, учитывая устойчивость файла к ошибкам.
Он пригласил сообщество SEO поразмышлять о причинах такого включения.
Ответы на пост Ильеса
Ответ сообщества SEO на пост Ильеса дает дополнительный контекст относительно практических последствий устойчивости к ошибкам в robots.txt и использования строчных комментариев.
Эндрю С., основатель Optimisey, подчеркнул полезность комментариев в строке для внутренней коммуникации, заявив:
«При работе над веб-сайтами вы можете увидеть комментарий к строке как примечание от разработчика о том, что он хочет, чтобы делала строка «disallow» в файле».
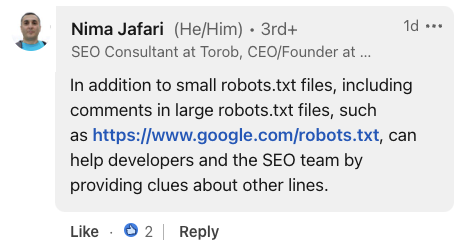
Нима Джафари, консультант по поисковой оптимизации, подчеркнул ценность комментариев при крупномасштабных внедрениях.
Он отметил, что в случае с обширными файлами robots.txt комментарии могут «помочь разработчикам и команде SEO, предоставляя подсказки о других строках».
 Скриншот из LinkedIn, июль 2024 г.
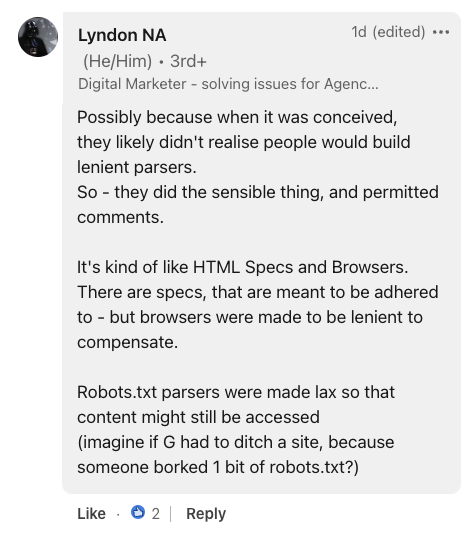
Скриншот из LinkedIn, июль 2024 г.Предоставляя исторический контекст, Линдон Н.А., цифровой маркетолог, сравнил robots.txt со спецификациями HTML и браузерами.
Он предположил, что допустимая погрешность файла, скорее всего, была преднамеренным выбором разработчика, заявив:
«Парсеры robots.txt были сделаны слабыми, чтобы к контенту все равно можно было получить доступ (представьте, что G пришлось бы закрыть сайт из-за того, что кто-то испортил 1 бит robots.txt?)».
 Скриншот из LinkedIn, июль 2024 г.
Скриншот из LinkedIn, июль 2024 г.Почему SEJ заботится
Понимание нюансов файла robots.txt может помочь вам лучше оптимизировать сайты.
Хотя устойчивость файла к ошибкам в целом полезна, она может привести к появлению неучтенных проблем, если не управлять ею тщательно.
Что делать с этой информацией
- Проверьте свой файл robots.txt.: Убедитесь, что он содержит только необходимые директивы и не содержит потенциальных ошибок или неправильных конфигураций.
- Будьте осторожны с правописанием: Хотя парсеры могут игнорировать опечатки, это может привести к непреднамеренному поведению сканирования.
- Используйте комментарии к строкам: Комментарии можно использовать для документирования файла robots.txt для дальнейшего использования.
Главное изображение: sutadism/Shutterstock
