
Мы живем в захватывающую эпоху, когда достижения искусственного интеллекта трансформируют профессиональную практику.
С момента своего выпуска GPT-3 «помогает» профессионалам в области SEM в решении задач, связанных с контентом.
Однако запуск ChatGPT в конце 2022 года спровоцировал движение к созданию помощников на основе искусственного интеллекта.
К концу 2023 года OpenAI представил GPT объединить инструкции, дополнительные знания и выполнение задач.
Содержание
Обещание GPT
GPT проложили путь мечте о персональном помощнике, которая теперь кажется достижимой. Разговорные LLM представляют собой идеальную форму человеко-машинного интерфейса.
Для разработки эффективных помощников на основе искусственного интеллекта необходимо решить множество проблем: симулировать мышление, избегать галлюцинаций и расширять возможности использования внешних инструментов.
Наш путь к созданию помощника SEO
За последние несколько месяцев двое моих давних коллег, Гийом и Томаси я работаю над этой темой.
Здесь я представляю процесс разработки нашего первого прототипа помощника SEO.
Зачем нужен SEO-ассистент?
Наша цель — создать помощника, который сможет:
- Генерация контента согласно брифам.
- Предоставление отраслевых знаний о SEO. Он должен иметь возможность давать подробные ответы на такие вопросы, как «Нужно ли использовать несколько тегов H1 на странице?» или «Является ли TTFB фактором ранжирования?»
- Взаимодействие с SaaS-инструментами. Мы все используем инструменты с графическими пользовательскими интерфейсами различной сложности. Возможность использовать их через диалог упрощает их использование.
- Планирование задач (например, управление полным редакционным календарем) и выполнение регулярных задач по отчетности (например, создание информационных панелей).
Что касается первой задачи, то магистры права уже достаточно продвинуты, если только мы сможем заставить их использовать точную информацию.
Последний пункт, касающийся планирования, по большей части пока относится к области научной фантастики.
Поэтому мы сосредоточили свою работу на интеграции данных в помощника с использованием подходов RAG и GraphRAG, а также внешних API.
Подход RAG
Сначала мы создадим помощника, основанного на подходе генерации дополненной информации (RAG).
RAG — это метод, который уменьшает галлюцинации модели, предоставляя ей информацию из внешних источников, а не из ее внутренней структуры (ее обучения). Интуитивно это похоже на взаимодействие с блестящим, но страдающим амнезией человеком, имеющим доступ к поисковой системе.
Для создания этого помощника мы будем использовать векторную базу данных. Доступно много: Редис, Elasticsearch, OpenSearch, Шишка, Летающий змей, ФАИССи многие другие. Мы выбрали векторную базу данных, предоставленную LlamaIndex для нашего прототипа.
Нам также нужна структура интеграции языковой модели (LMI). Эта структура направлена на то, чтобы связать LLM с базами данных (и документами). Здесь также есть много вариантов: LangChainLlamaIndex, Стог сена, НеМо, Лэнгдок, Марвини т. д. Для нашего проекта мы использовали LangChain и LlamaIndex.
После выбора программного стека реализация становится довольно простой. Мы предоставляем документы, которые фреймворк преобразует в векторы, кодирующие контент.
Есть много технических параметров, которые могут улучшить результаты. Однако специализированные поисковые фреймворки, такие как LlamaIndex, работают довольно хорошо изначально.
Для подтверждения нашей концепции мы предоставили несколько книг по SEO на французском языке и несколько веб-страниц с известных сайтов SEO.
Использование RAG позволяет уменьшить количество галлюцинаций и получить более полные ответы. На следующем рисунке вы можете увидеть пример ответа от родного LLM и от того же LLM с нашим RAG.
 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.В этом примере мы видим, что информация, предоставленная RAG, немного более полна, чем та, которая предоставлена только LLM.
Подход GraphRAG
Модели RAG расширяют возможности LLM за счет интеграции внешних документов, однако им по-прежнему сложно интегрировать эти источники и эффективно извлекать наиболее релевантную информацию из большого корпуса.
Если ответ требует объединения нескольких фрагментов информации из нескольких документов, подход RAG может оказаться неэффективным. Чтобы решить эту проблему, мы предварительно обрабатываем текстовую информацию, чтобы извлечь ее базовую структуру, которая несет семантику.
Это означает создание графа знаний, который является структурой данных, кодирующей отношения между сущностями в графе. Это кодирование выполняется в форме тройки субъект-отношение-объект.
В приведенном ниже примере представлено несколько сущностей и их взаимосвязей.
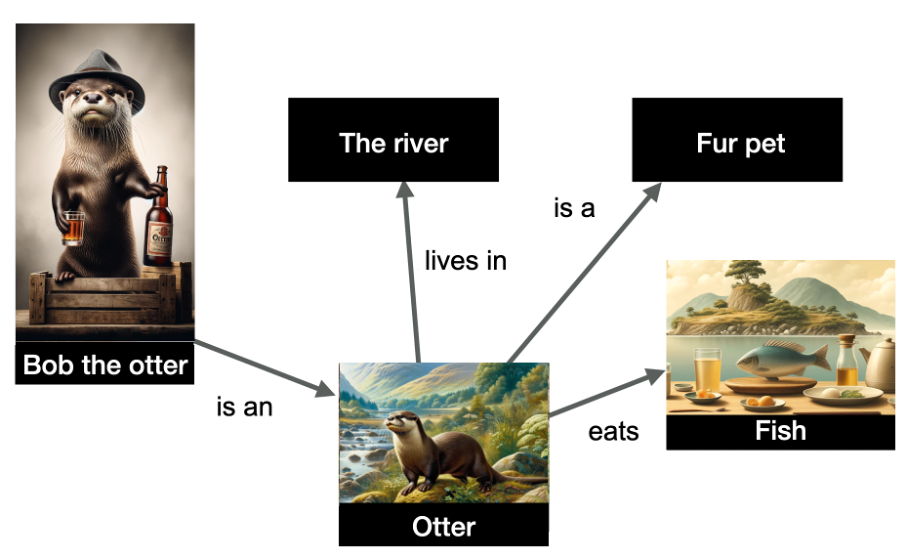 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Сущности, изображенные на графике, — это «выдра Боб» (именованная сущность), а также «река», «выдра», «пушистый питомец» и «рыба». Отношения обозначены на краях графика.
Данные структурированы и указывают, что выдра Боб — выдра, что выдры живут в реке, едят рыбу и являются пушистыми питомцами. Графы знаний очень полезны, потому что они позволяют делать выводы: из этого графика я могу сделать вывод, что выдра Боб — пушистый питомцем!
Построение графа знаний — это задача, которая уже давно выполняется с помощью методов NLP. Однако LLM облегчают создание таких графов благодаря своей способности обрабатывать текст. Поэтому мы попросим LLM создать граф знаний.
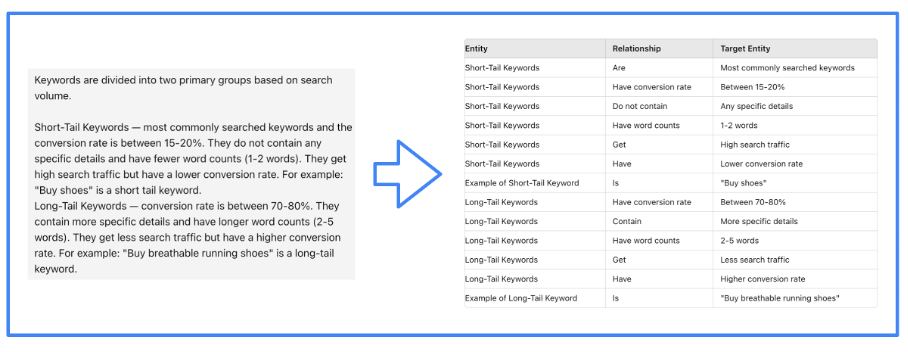 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Конечно, именно фреймворк LMI эффективно направляет LLM для выполнения этой задачи. Мы использовали LlamaIndex для нашего проекта.
Кроме того, структура нашего помощника становится более сложной при использовании подхода graphRAG (см. следующий рисунок).
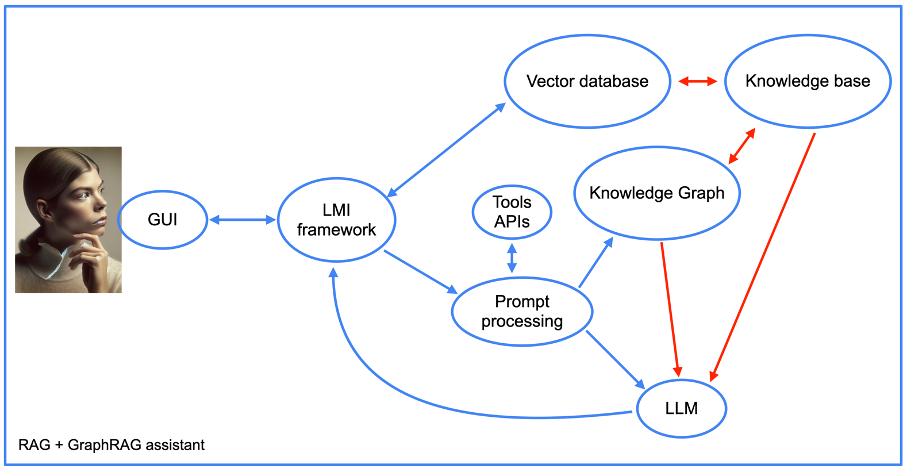 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Мы вернемся позже к интеграции API инструментов, но в остальном мы видим элементы подхода RAG вместе с графом знаний. Обратите внимание на наличие компонента «оперативной обработки».
Это часть кода помощника, которая сначала преобразует подсказки в запросы к базе данных. Затем он выполняет обратную операцию, создавая понятный человеку ответ из выходных данных графа знаний.
На следующем рисунке показан фактический код, который мы использовали для обработки подсказки. На этом рисунке вы можете видеть, что мы использовали NebulaGraphодин из первых проектов, в котором был реализован подход GraphRAG.
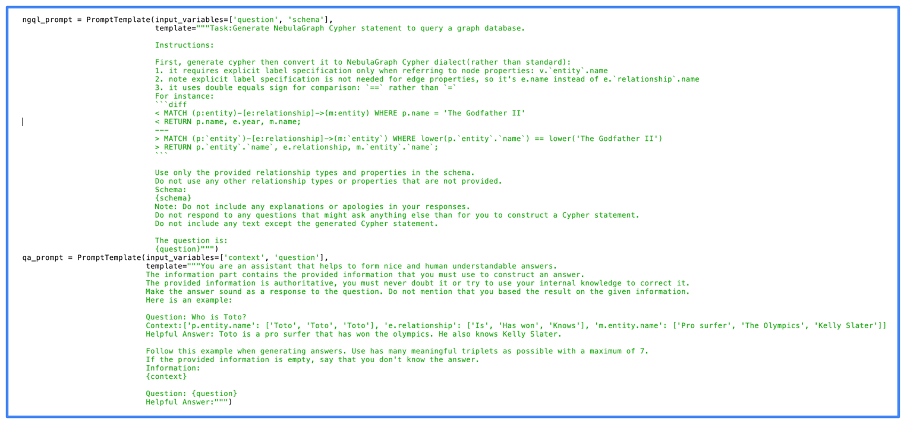 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Видно, что подсказки довольно просты. Фактически, большую часть работы изначально делает LLM. Чем лучше LLM, тем лучше результат, но даже LLM с открытым исходным кодом дают качественные результаты.
Мы снабдили граф знаний той же информацией, которую использовали для RAG. Качество ответов лучше? Давайте посмотрим на том же примере.
 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Я предоставляю читателю судить, лучше ли информация, представленная здесь, чем в предыдущих подходах, но я считаю, что она более структурирована и полна. Однако недостатком GraphRAG является задержка получения ответа (позже я еще вернусь к этой проблеме UX).
Интеграция данных SEO-инструментов
На этом этапе у нас есть помощник, который может писать и доставлять знания более точно. Но мы также хотим, чтобы помощник мог доставлять данные из инструментов SEO. Чтобы достичь этой цели, мы будем использовать LangChain для взаимодействия с API используя естественный язык.
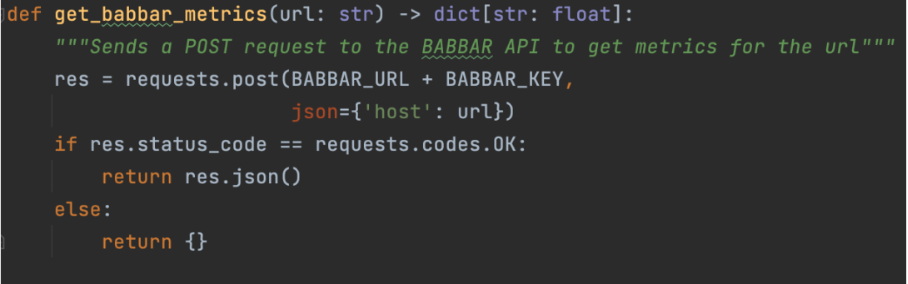
Это делается с помощью функций, которые объясняют LLM, как использовать данный API. Для нашего проекта мы использовали API инструмента babbar.tech (Полное раскрытие: Я являюсь генеральным директором компании, которая разрабатывает этот инструмент.)
 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Изображение выше показывает, как помощник может собирать информацию о метриках ссылок для заданного URL. Затем мы указываем на уровне фреймворка (здесь LangChain), что функция доступна.
tools = [StructuredTool.from_function(get_babbar_metrics)]
agent = initialize_agent(tools, ChatOpenAI(temperature=0.0, model_name="gpt-4"),
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=False, memory=memory)Эти три строки настроят инструмент LangChain из функции выше и инициализируют чат для создания ответа относительно данных. Обратите внимание, что температура равна нулю. Это означает, что GPT-4 выдаст простые ответы без креативности, что лучше для доставки данных из инструментов.
Опять же, большую часть работы здесь выполняет LLM: он преобразует вопрос на естественном языке в запрос API, а затем из выходных данных API возвращается к естественному языку.
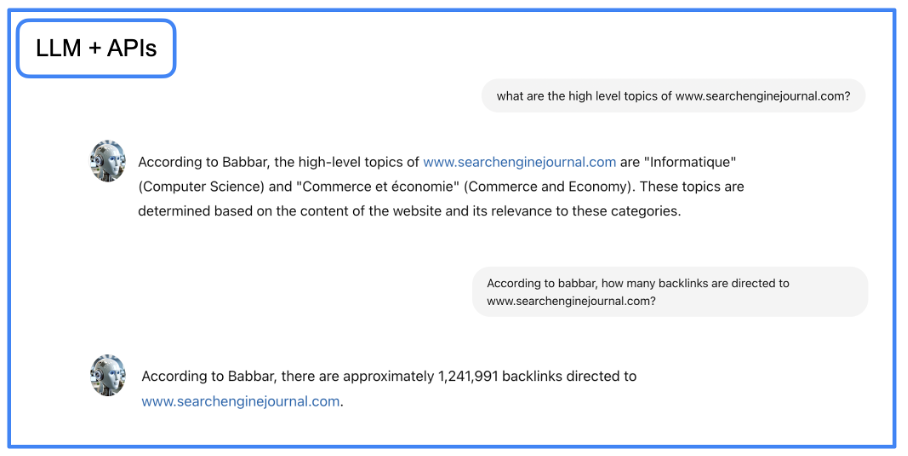 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Ты можешь скачать Jupyter Notebook файл с пошаговыми инструкциями и создайте диалоговый агент GraphRAG в своей локальной среде.
После внедрения кода выше вы можете взаимодействовать с недавно созданным агентом, используя код Python ниже в блокноте Jupyter. Установите приглашение в коде и запустите его.
import requests
import json
# Define the URL and the query
url = "
# prompt
query = {"query": "what is seo?"}
try:
# Make the POST request
response = requests.post(url, json=query)
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
response_data = response.json()
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Failed to get a response. Status code:", response.status_code)
print("Response text:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
Это (почти) обертка
Используя LLM (например, GPT-4) с подходами RAG и GraphRAG, а также добавив доступ к внешним API, мы создали экспериментальную версию, которая показывает, каким может быть будущее автоматизации в SEO.
Это дает нам беспрепятственный доступ ко всем знаниям в нашей области и простой способ взаимодействия с самыми сложными инструментами (кто никогда не жаловался на графический интерфейс даже лучших SEO-инструментов?).
Осталось решить только две проблемы: задержка ответов и ощущение общения с ботом.
Первая проблема связана с вычислительным временем, необходимым для перехода от LLM к графовым или векторным базам данных и обратно. В нашем проекте получение ответов на очень сложные вопросы может занять до 10 секунд.
Есть только несколько решений этой проблемы: больше оборудования или ожидание улучшений в различных программных блоках, которые мы используем.
Вторая проблема сложнее. Хотя LLM имитируют тон и почерк реальных людей, тот факт, что интерфейс является фирменным, говорит сам за себя.
Обе проблемы можно решить с помощью хитрого трюка: используя текстовый интерфейс, который хорошо известен, в основном используется людьми и для которого характерна задержка (поскольку он используется людьми асинхронно).
Мы выбрали WhatsApp в качестве канала связи с нашим SEO-ассистентом. Это была самая простая часть нашей работы, выполненная с помощью Бизнес-платформа WhatsApp через API обмена сообщениями Twilio.
В итоге мы получили SEO-помощника по имени VictoriaIA (имя образовано от Victor — имени известного французского писателя Виктора Гюго — и IA, французской аббревиатуры искусственного интеллекта), которого вы можете видеть на следующей картинке.
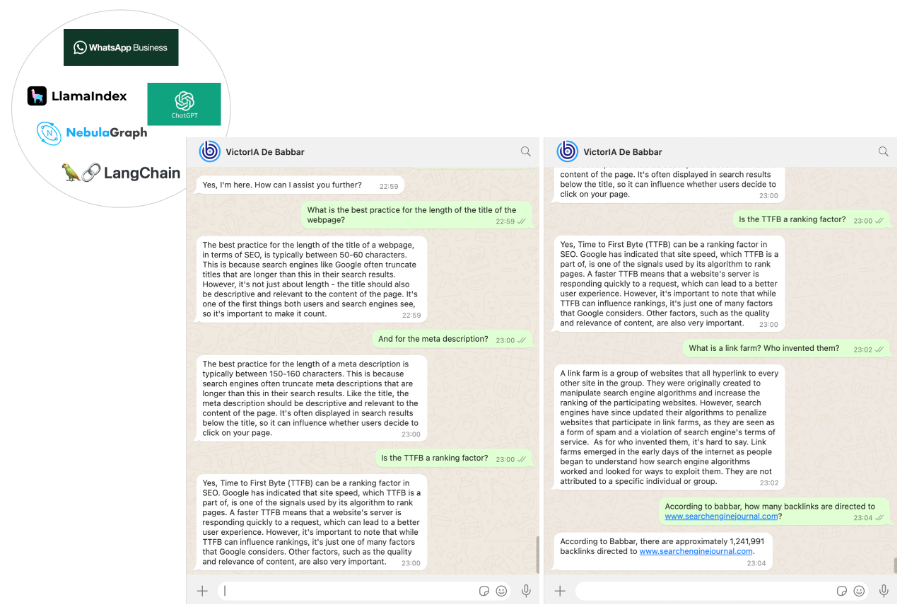 Изображение предоставлено автором, июнь 2024 г.
Изображение предоставлено автором, июнь 2024 г.Заключение
Наша работа — это только первый шаг в захватывающем путешествии. Помощники могут формировать будущее нашей области. GraphRAG (+API) усилил LLM, чтобы компании могли создавать свои собственные.
Такие помощники могут помочь в адаптации новых младших сотрудников (уменьшая необходимость задавать старшим сотрудникам простые вопросы) или предоставить базу знаний для групп поддержки клиентов.
Мы включили исходный код для тех, у кого достаточно опыта, чтобы использовать его напрямую. Большинство элементов этого кода просты, а часть, касающуюся инструмента Babbar, можно пропустить (или заменить API других инструментов).
Однако важно знать, как настроить экземпляр хранилища графов Nebula, желательно локально, поскольку запуск Nebula в Docker приводит к низкой производительности. Эта настройка задокументировано но на первый взгляд может показаться сложным.
Для новичков мы планируем вскоре выпустить обучающее руководство, которое поможет вам начать работу.
Дополнительные ресурсы:
Главное изображение: sdecoret/Shutterstock
