Парсинг, или сбор данных, является важной частью автоматического анализа и обработки текстов. В современном информационном мире огромное количество статей, новостей и других текстовых материалов публикуется каждый день. Чтобы эффективно извлекать и анализировать информацию из этих текстов, необходимо использовать специальные методы и инструменты.

Одним из эффективных методов является парсинг HTML-страниц, которые часто содержат тексты статей. При помощи парсинга можно извлекать нужные нам данные, такие как заголовки, тексты, даты публикаций и другие метаданные. Для этого используются различные технологии, такие как XPath, CSS-селекторы и регулярные выражения. Кроме того, можно использовать уже готовые библиотеки и инструменты, которые упростят процесс парсинга.
Одним из таких инструментов является, например, библиотека Beautiful Soup для языка Python. Она предоставляет простой и удобный интерфейс для парсинга HTML-страниц. Также существуют другие инструменты, такие как Scrapy и Selenium, которые позволяют автоматизировать и упростить процесс сбора данных из статей и других текстовых материалов.
В данной статье рассмотрим различные методы парсинга HTML-страниц, а также популярные инструменты для автоматического анализа и обработки статей. Будем изучать как использовать эти методы и инструменты для решения различных задач, связанных с извлечением информации из статей и их последующей обработкой. Парсинг является важным эффективным средством для получения и обработки данных, и его знание является необходимым для работы с текстовыми материалами в современном информационном мире.
Содержание
Парсинг статей: возможности и преимущества
Парсинг статей – это процесс извлечения структурированных данных из текстовых документов с использованием специальных алгоритмов и инструментов. Парсинг статей активно применяется в области автоматического анализа и обработки информации, помогая извлекать нужные данные из больших объемов текстов и использовать их для разных целей.
Один из главных преимуществ парсинга статей – это автоматизация процесса обработки информации. Вместо того, чтобы вручную читать и анализировать каждую статью, парсинг позволяет быстро извлекать нужные данные и использовать их для автоматического анализа или дальнейшей обработки. Это существенно ускоряет работу и позволяет экономить время и ресурсы.
Второе преимущество парсинга статей – это возможность структурирования полученных данных. Парсинг позволяет извлекать информацию из различных разделов статей, таких как заголовки, подзаголовки, параграфы, списки и таблицы. Структурированные данные могут быть использованы для создания баз данных, построения графиков и диаграмм, а также для автоматического создания сводных отчетов.
Кроме того, парсинг статей позволяет извлекать специфическую информацию, например, имена авторов, даты публикации, ключевые слова и цитаты. Полученные данные могут быть использованы для анализа статей по определенным критериям, таким как авторы, тематика, рейтинг и т.д., что помогает в оценке качества и релевантности статей.
Еще одним преимуществом парсинга статей является возможность автоматического поиска и фильтрации информации. Парсинг позволяет извлекать данные только по определенным параметрам или шаблонам, что помогает исключить ненужную информацию и сосредоточиться на наиболее значимых моментах. Это особенно полезно при обработке больших объемов статей или при работе с информацией, требующей постоянного обновления и анализа.
Таким образом, парсинг статей предоставляет намножество возможностей для автоматического анализа, обработки и использования информации. С его помощью можно быстро извлекать нужные данные, структурировать их и использовать для различных целей, таких как анализ, исследование, создание сводных отчетов и многое другое.
Автоматический анализ
Автоматический анализ – это процесс, в котором компьютерные алгоритмы и программы используются для обработки и интерпретации данных. При автоматическом анализе статей применяются методы и инструменты парсинга, которые позволяют извлекать и структурировать информацию из текстовых документов.
Одним из ключевых этапов автоматического анализа является парсинг, или синтаксический анализ. Парсинг позволяет разбить текст на составляющие его элементы – слова, предложения, абзацы и так далее. Это позволяет провести более детальный анализ содержания статьи.
Для автоматического анализа статей также часто используются методы обработки естественного языка (Natural Language Processing, NLP). Они позволяют компьютеру понимать и интерпретировать человеческий язык, анализировать его смысл, синтаксис и семантику.
Важным этапом автоматического анализа статей является извлечение ключевых слов и фраз. Это позволяет обнаруживать основные темы и смысловые единицы в тексте. Извлеченные ключевые слова и фразы могут быть использованы для категоризации и классификации статей, а также для поиска и анализа текстов с заданной тематикой.
Для эффективного автоматического анализа статей существуют различные инструменты и библиотеки программного обеспечения. Некоторые из них предоставляют API для автоматического парсинга и анализа статей, что позволяет интегрировать их в различные приложения и сервисы.
| Преимущества автоматического анализа статей | Недостатки автоматического анализа статей |
|---|---|
|
|
В целом, автоматический анализ статей является мощным инструментом для обработки и интерпретации текстовых данных. Он позволяет автоматизировать процессы анализа больших объемов информации, а также повышает точность и эффективность этого анализа.
Эффективные методы парсинга
Парсинг, или разбор, является одной из основных задач в области обработки данных. Он позволяет извлечь информацию из исходного текста и представить ее в удобной структурированной форме. Для эффективного парсинга существуют различные методы, которые можно использовать в зависимости от поставленных задач.
1. Регулярные выражения
Регулярные выражения являются удобным и эффективным инструментом для поиска и извлечения информации из текста. Они позволяют задать шаблон и найти все соответствующие ему участки в тексте. Регулярные выражения широко используются для парсинга HTML-кода, текстовых файлов, логов и других текстовых данных.
2. XML-парсеры
XML-парсеры являются инструментами для разбора XML-документов. Они позволяют извлекать информацию из XML-документа, а также создавать структуры данных на основе его содержимого. XML-парсеры поддерживают различные виды парсинга, такие как DOM (Document Object Model) и SAX (Simple API for XML), что позволяет выбрать наиболее подходящий под конкретную задачу подход.
3. HTML-парсеры
HTML-парсеры предназначены для разбора HTML-кода и извлечения информации из него. Они позволяют извлекать содержимое тегов, атрибуты, структуры данных и другую информацию из HTML-страниц. HTML-парсеры широко используются для создания веб-скраперов, автоматической обработки HTML-страниц и других задач, связанных с анализом и обработкой веб-контента.
4. Определение синтаксической структуры
Парсинг может быть использован для определения синтаксической структуры текста. Например, парсеры естественного языка позволяют выделить предложения, слова и другие элементы языка. Это позволяет проводить различные анализы, такие как выделение ключевых слов, определение частей речи и т. д. Определение синтаксической структуры текста является одной из основных задач в обработке естественного языка и находит применение в различных областях, таких как машинный перевод, анализ тональности текста и других.
5. Методы машинного обучения
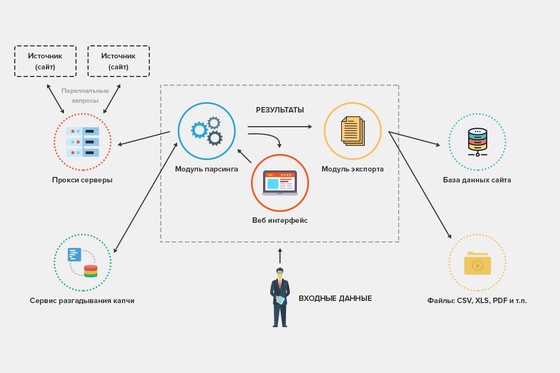
Методы машинного обучения можно использовать для парсинга текстовых данных. Например, методы классификации позволяют выделить различные категории текста, а методы разметки последовательностей (sequence labeling) позволяют определить смысловые единицы в тексте. Машинное обучение позволяет создавать модели, которые могут обрабатывать большие объемы данных и находить сложные зависимости.
Выбор эффективного метода парсинга зависит от поставленной задачи, особенностей исходных данных и доступных ресурсов. В некоторых случаях может быть полезно комбинировать несколько методов для достижения наилучшего результата.
Инструменты для парсинга статей
Парсинг статей — это процесс извлечения и структурирования информации из текстовых документов. Существует множество инструментов, которые могут быть использованы для парсинга статей с различных источников. Ниже приведен список наиболее популярных инструментов для парсинга статей:
- Beautiful Soup: Это библиотека для языка программирования Python, которая позволяет легко извлекать данные из HTML и XML документов. Он обеспечивает мощные средства для навигации и поиска информации в структурированных документах.
- Scrapy: Scrapy — это фреймворк для извлечения данных и автоматического скрапинга, написанный на Python. Он предоставляет набор инструментов для создания веб-пауков, которые могут извлекать данные с веб-сайтов.
- Parser: Parser — это модуль для языка программирования JavaScript, который позволяет разбирать HTML и XML документы. Он предоставляет удобный интерфейс для работы с различными типами данных в документах.
Кроме того, существуют и другие инструменты для парсинга статей, такие как lxml, Jsoup, PHP Simple HTML DOM Parser и т. д. Каждый из этих инструментов имеет свои преимущества и недостатки, и выбор инструмента зависит от конкретных потребностей проекта.
Парсинг статей может быть полезен для различных целей, включая автоматическую обработку текстов, сбор данных для анализа, создание каталогов и многое другое. Использование правильного инструмента для парсинга статей может упростить процесс и повысить эффективность работы.
Независимо от выбора инструмента, важно помнить о законности и этичности сбора данных. При использовании парсера для извлечения информации с веб-сайтов важно соблюдать правила использования и не нарушать авторские права или политики сайта.
Видео:
Практикум по xPath: простой, быстрый и бесплатный способ парсить сайты прямо в Google Таблицах
