
Мы знаем, что Google использует машинное обучение, а в последнее время и искусственный интеллект, для создания описаний фрагментов результатов поиска. Что ж, вот пример того, как Google получил фрагмент не просто неправильный, но и совершенно оскорбительный.
Эндрю Кок-Старки разместил пример на LinkedIn Google не использует текст на странице, а называет страницу в результатах поиска «очень многословной версией» того, о чем идет речь в статье. И нет, этих слов нет на странице.
Спасибо, Google, за ваше мнение о стиле написания этого контента…
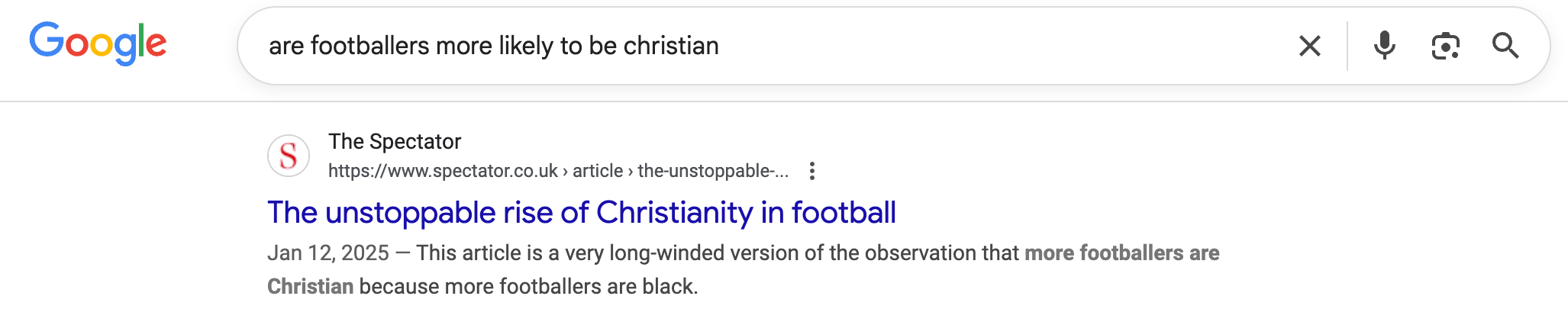
Вот этот фрагмент:
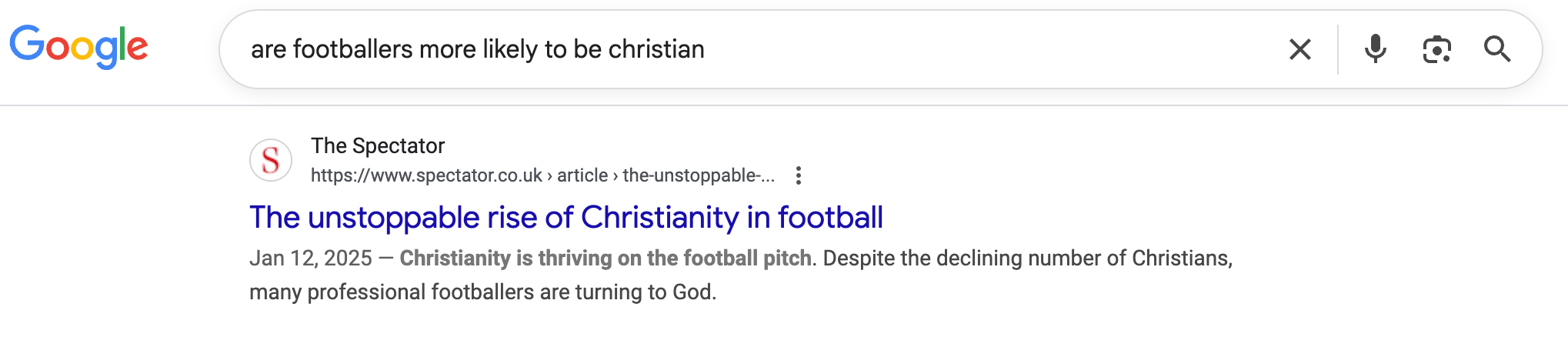
Мне также удалось сгенерировать версию без AI, которая вместо описания использует контент со страницы:
Андрей написал:
Мы все видели, как Google переписывал метаописания, но это меня остановило.
«Курт» — вот один из способов описать это. Я не уверен, что Зритель будет в восторге от краткого содержания?
Я проверил и дважды проверил код страницы, он даже близко не соответствует предоставленному метаописанию.
Собственный Google документация говорит: «Фрагменты в основном создаются из самого содержимого страницы. Однако Google иногда использует HTML-элемент мета-описания, если он может дать пользователям более точное описание страницы, чем контент, взятый непосредственно со страницы».
Но, думаю, не в этом случае…
При этом это своего рода дикий пример того, как ИИ высказывает нам свои мысли о содержании этой страницы.
Конечно, SEO-сообщество в восторге от этого в разделе комментариев к этому посту.
Обсуждение на форуме по адресу LinkedIn.
