
Когда диалоговые ИИ, такие как ChatGPT, Perplexity или Google AI Mode, генерируют фрагменты или сводки ответов, они не пишут с нуля, они выбирают, сжимают и заново собирают то, что предлагают веб-страницы. Если ваш контент не оптимизирован для SEO и не индексируется, он вообще не попадет в генеративный поиск. Поиск, каким мы его знаем, теперь является функцией искусственного интеллекта.
Но что, если ваша страница не «предлагает» себя в машиночитаемой форме? Вот тут-то и приходят на помощь структурированные данные — не только в качестве SEO-концепции, но и в качестве основы для ИИ, позволяющей надежно выбирать «правильные факты». В нашем сообществе возникла некоторая путаница, и в этой статье я:
- пройти контролируемые эксперименты на 97 веб-страницах, показывающие, как структурированные данные улучшают согласованность фрагментов и контекстную релевантность,
- сопоставьте эти результаты с нашей семантической структурой.
В последние месяцы многие спрашивали меня, используют ли LLM структурированные данные, и я повторял снова и снова, что LLM не использует структурированные данные, поскольку у него нет прямого доступа к всемирной паутине. LLM использует инструменты для поиска в Интернете и загрузки веб-страниц. Его инструменты – в большинстве случаев – значительно выигрывают от индексации структурированных данных.
Согласно нашим ранним результатам, структурированные данные повышают согласованность фрагментов и контекстную релевантность в GPT-5. Это также намекает на расширение эффективного Wordlim конверт — это скрытая директива GPT-5, которая определяет, сколько слов ваш контент получит в ответ. Представьте это как квоту на видимость вашего ИИ, которая увеличивается, когда контент становится богаче и лучше типизирован. Вы можете прочитать больше об этой концепции, которую я впервые изложено в LinkedIn.
Содержание
Почему это важно сейчас
- Ограничения Wordlim: Стеки ИИ работают со строгим бюджетом токенов/персонажей. Двусмысленность приводит к потере бюджета; напечатанные факты сохраняют его.
- Устранение неоднозначности и обоснование: Schema.org сокращает пространство поиска модели («это рецепт/продукт/статья»), делая выбор более безопасным.
- Графы знаний (КГ): Schema часто предоставляет информацию KG, с которыми системы ИИ консультируются при поиске фактов. Это мост от веб-страниц к рассуждениям агента.
Мой личный тезис заключается в том, что мы хотим рассматривать структурированные данные как уровень инструкций для ИИ. Это не так «ранг для тебя», это стабилизирует то, что ИИ может сказать о вас.
Дизайн эксперимента (97 URL-адресов)
Хотя размер выборки был небольшим, я хотел посмотреть, как на самом деле работает уровень поиска ChatGPT при использовании из собственного интерфейса, а не через API. Для этого я попросил GPT-5 выполнить поиск и открыть пакет URL-адресов с разных типов веб-сайтов и вернуть необработанные ответы.
Вы можете предложить GPT-5 (или любой системе искусственного интеллекта) показать дословный вывод своих внутренних инструментов, используя простой мета-подсказку. Собрав ответы поиска и выборки для каждого URL-адреса, я запустил Рабочий процесс агента WordLift [disclaimer, our AI SEO Agent] проанализировать каждую страницу, проверив, содержит ли она структурированные данные, и, если да, определить конкретные обнаруженные типы схем.
В результате этих двух шагов был получен набор данных из 97 URL-адресов, снабженных ключевыми полями:
- has_sd → Флаг True/False для наличия структурированных данных.
- схема_классы → обнаруженный тип (например, Рецепт, Продукт, Артикул).
- search_raw → фрагмент «стиля поиска», представляющий то, что показал инструмент поиска AI.
- open_raw → сводка сборщика или структурный просмотр страницы с помощью GPT-5.
Используя подход «LLM как судья» на базе Gemini 2.5 Pro, я затем проанализировал набор данных, чтобы выделить три основных показателя:
- Последовательность: распределение длин фрагментов search_raw (ящичная диаграмма).
- Контекстуальная значимость: охват ключевых слов и полей в open_raw по типу страницы (рецепт, электронная почта, статья).
- Оценка качества: консервативный индекс 0–1, объединяющий наличие ключевых слов, основные сигналы NER (для электронной коммерции) и эхо схемы в результатах поиска.
Скрытая квота: распаковка»Wordlim»
Выполняя эти тесты, я заметил еще одну тонкую закономерность, которая может объяснить, почему структурированные данные приводят к более согласованным и полным фрагментам. Внутри конвейера поиска GPT-5 есть внутренняя директива, неофициально известная как wordlim: динамическая квота, определяющая, какой объем текста с одной веб-страницы может превратиться в сгенерированный ответ.
На первый взгляд, это действует как ограничение на количество слов, но оно адаптивное. Чем богаче и лучше типизирован контент страницы, тем больше места он занимает в окне синтеза модели.
Из моих постоянных наблюдений:
- Неструктурированный контент (например, стандартная запись в блоге) обычно содержит около 200 слов.
- Структурированный контент (например, разметка продукта, фиды) занимает около 500 слов.
- Плотные, авторитетные источники (API, исследовательские статьи) может достигать более 1000 слов.
Это не произвольно. Ограничение помогает системам ИИ:
- Поощряйте синтез различных источников, а не копирование.
- Избегайте проблем с авторскими правами.
- Делайте ответы краткими и читабельными.
Тем не менее, это также открывает новые горизонты для SEO: ваши структурированные данные эффективно повышают вашу квоту видимости. Если ваши данные не структурированы, вы ограничены минимумом; если это так, вы предоставляете ИИ больше доверия и больше места для продвижения вашего бренда.
Хотя набор данных еще недостаточно велик, чтобы быть статистически значимым по каждой вертикали, ранние закономерности уже ясны и действенны.
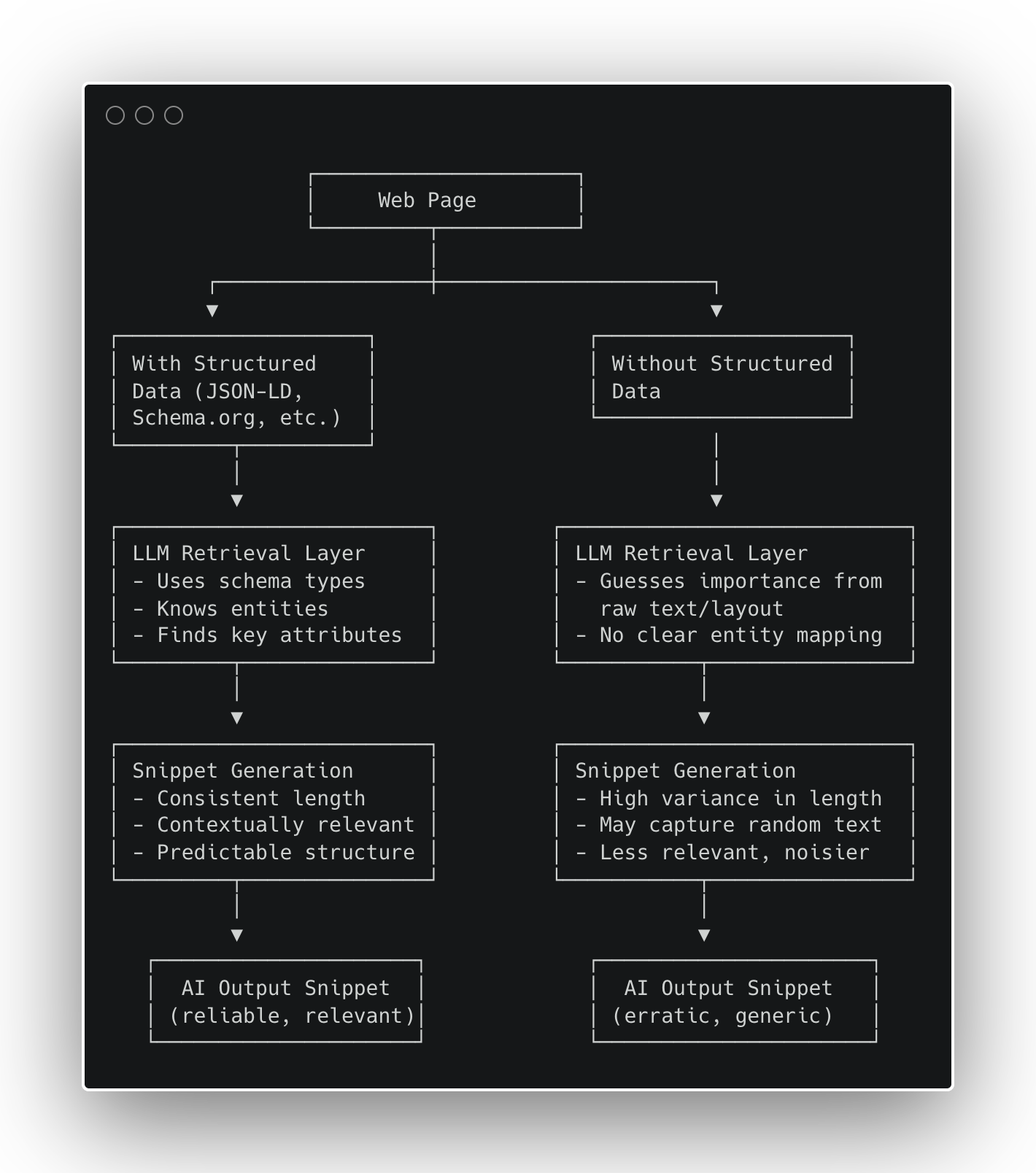 Рисунок 1. Как структурированные данные влияют на создание фрагментов кода ИИ (изображение автора, октябрь 2025 г.)
Рисунок 1. Как структурированные данные влияют на создание фрагментов кода ИИ (изображение автора, октябрь 2025 г.)Результаты
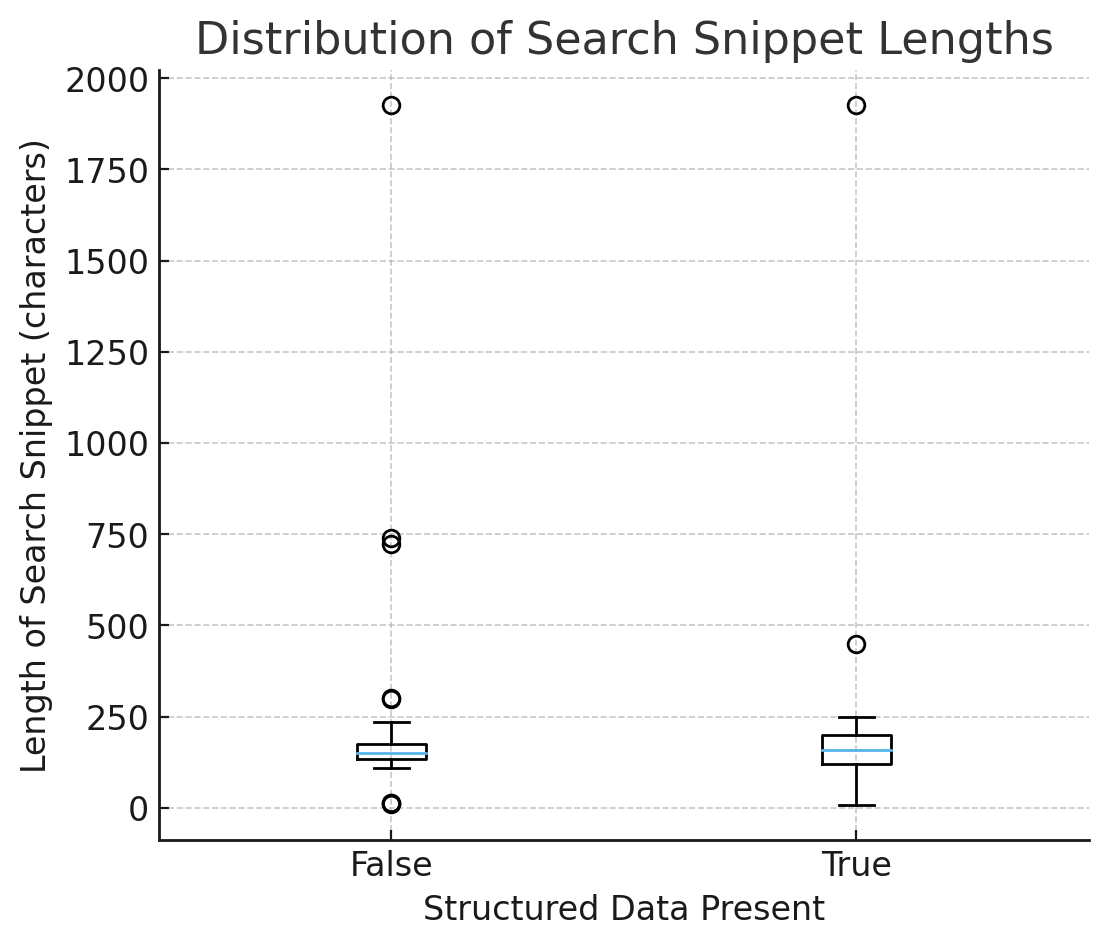 Рисунок 2. Распределение длин поисковых фрагментов (изображение автора, октябрь 2025 г.)
Рисунок 2. Распределение длин поисковых фрагментов (изображение автора, октябрь 2025 г.)1) Последовательность: фрагменты более предсказуемы со схемой
На диаграмме длины фрагмента поиска (со структурированными данными и без него):
- Медианы аналогичны → схема в среднем не делает фрагменты длиннее или короче.
- Спред (IQR и усы) более узкий, когда has_sd = Истина → меньше хаотичных результатов, более предсказуемые сводки.
Интерпретация: Структурированные данные не увеличивают длину; это уменьшает неопределенность. Модели по умолчанию используют типизированные безопасные факты вместо догадок на основе произвольного HTML.
2) Контекстуальная релевантность: извлечение направляющих схем
- Рецепты: С Рецепт схема, сводки выборки, скорее всего, будут включать ингредиенты и этапы. Четкий, измеримый подъем.
- Электронная торговля: Инструмент поиска часто отображает поля JSON‑LD (например, совокупный рейтинг, предложение, бренд) свидетельство того, что схема прочитана и обнаружена. Сводки выборки искажают точные названия продуктов, а не общие термины, такие как «цена», но привязка идентичности к схеме сильнее.
- Статьи: Небольшая, но ощутимая выгода (более вероятно появление автора/даты/заголовка).
3) Показатель качества (все страницы)
Усреднение оценки 0–1 по всем страницам:
- Нет схемы → ~0,00
- Со схемой → положительный подъем, обусловленный в основном рецептами и некоторыми статьями.
Даже там, где средние значения выглядят схожими, дисперсия исчезает из-за схемы. В мире искусственного интеллекта, ограниченном Wordlim и накладные расходы на поиск, низкая дисперсия является конкурентным преимуществом.
За пределами согласованности: более обширные данные расширяют возможности Wordlim (ранний сигнал)
Хотя набор данных еще недостаточно велик для проверки значимости, мы заметили следующую закономерность:
Страницы с более богатыми, многокомпонентными структурированными данными, как правило, перед усечением дают немного более длинные и плотные фрагменты.
Гипотеза: типизированные взаимосвязанные факты (например, Товар + Предложение + Бренд + СовокупныйРейтинг или Статья + автор + дата публикации) помогают моделям расставлять приоритеты и сжимать ценную информацию, эффективно увеличивая полезный бюджет токенов для этой страницы.
Страницы без схемы чаще преждевременно обрезаются, вероятно, из-за неуверенности в релевантности.
Следующий шаг: мы измерим взаимосвязь между семантическим богатством (количеством различных объектов/атрибутов Schema.org) и эффективной длиной фрагмента. В случае подтверждения структурированные данные не только стабилизируют фрагменты, но и увеличивают информационную пропускную способность при постоянном ограничении количества слов.
От схемы к стратегии: Учебное пособие
Мы структурируем сайты как:
- Граф сущностей (Схема/GS1/Статьи/…): продукты, предложения, категории, совместимость, местоположение, политики;
- Лексический граф: фрагментированная копия (инструкции по уходу, руководства по размерам, часто задаваемые вопросы), связанная с объектами.
Почему это работает: Уровень сущностей дает ИИ безопасную основу; лексический уровень предоставляет многократно используемые доказательства, которые можно цитировать. Вместе они обеспечивают точностьWordlim ограничения.
Вот как мы преобразуем эти результаты в повторяемую инструкцию по SEO для брендов, работающих в условиях ограничений в области обнаружения ИИ.
- Отправка JSON‑LD для основных шаблонов
- Рецепты → Рецепт (ингредиенты, инструкция, выход, время).
- Товары → Продукт + предложение (бренд, GTIN/SKU, цена, наличие, рейтинги).
- Статьи → Статья/Новостная статья (заголовок, автор, датаОпубликовано).
- Унифицировать сущность + лексику
Храните спецификации, часто задаваемые вопросы и текст политики в виде фрагментов и связанных с ними объектов. - Укрепить поверхность фрагмента
Факты должны быть согласованными в видимом HTML и JSON‑LD; держите важные факты в секрете и стабильно. - Инструмент
Отслеживайте дисперсию, а не только средние значения. Сравните охват ключевых слов/полей в сводках машин по шаблону.
Заключение
Структурированные данные не меняют средний размер фрагментов AI; это меняет их уверенность. Он стабилизирует резюме и формирует то, что они включают. В ГПТ-5, особенно в агрессивных условиях Wordlim При таких условиях эта надежность приводит к более качественным ответам, меньшему количеству галлюцинаций и большей заметности бренда в результатах, полученных с помощью ИИ.
Для оптимизаторов и продуктовых команд вывод ясен: относитесь к структурированным данным как к базовой инфраструктуре. Если вашим шаблонам по-прежнему не хватает четкой семантики HTML, не переходите сразу к JSON-LD: сначала закрепите фундамент. Начните с очистки разметки, а затем наложите структурированные данные поверх нее, чтобы обеспечить семантическую точность и возможность долгосрочного обнаружения. В поиске ИИ семантика — это новая область поверхности.
Дополнительные ресурсы:
Рекомендованное изображение: TierneyMJ/Shutterstock
