
«Заблокирован robots.txt.»
«Индексирован, хотя и заблокирован robots.txt».
Эти два ответа от консоли поиска Google разделили специалистов SEO, так как отчеты об ошибках Google Search Console (GSC) стали предметом.
Это должно быть урегулировано раз и навсегда. Игра на.
Содержание
- 1 В чем разница между «заблокированным robots.txt» против «индексированного, хотя и заблокированного robots.txt»?
- 2 Мой URL Действительно Заблокировано от поисковых систем, если я запрещаю его в файле robots.txt?
- 3 Как исправить «заблокирован robots.txt» в консоли поиска Google?
- 3.1 Вручную просмотрите все страницы, помеченные в «Заблокированные robots.txt’Report
- 3.2 Определите, должны ли вы заблокировать URL -адрес из поисковых систем
- 3.3 Удалите директиву Diswalling с robots.txt, если вы случайно добавили ее по ошибке
- 3.4 Запрос на то, чтобы решить ваш файл robots.txt
- 3.5 Отслеживать производительность до и после
- 4 Как исправить «индексированные», хотя и заблокирован Robots.txt ‘в консоли поиска Google?
- 4.1 Вручную просмотрите все страницы, помеченные в «Индексированном, хотя и заблокированном отчету robots.txt ‘
- 4.2 Определите, должны ли вы заблокировать URL -адрес из поисковых систем
- 4.3 Удалить Директиву DISLALIN
- 4.4 Добавьте тег NoIndex, если вы хотите, чтобы страница была полностью удалена из поисковых систем
- 4.5 Зачем мне добавлять тег noindex вместо использования директивы Dislower в robots.txt?
- 4.6 Должен ли я включить как тег NoIndex, так и директиву DISLALING на один и тот же URL?
- 5 Создание четкой стратегии ползания для вашего сайта — это способ избежать ошибок robots.txt в консоли поиска Google
В чем разница между «заблокированным robots.txt» против «индексированного, хотя и заблокированного robots.txt»?
Существует одно важное различие между «заблокированным robots.txt» и «Indexted, хотя и заблокировано robots.txt».
Индексация.
«Заблокирован Robots.txt» означает, что ваши URL -адреса не появятся в поиске Google.
«Индексированный, хотя и заблокирован Robots.txt» означает, что ваши URL -адреса индексируются и появятся в поиске Google, даже если вы пытались заблокировать URL -адреса в файле robots.txt.
Мой URL Действительно Заблокировано от поисковых систем, если я запрещаю его в файле robots.txt?
Ответ: Нет.
Ни один URL -адрес не полностью заблокирован от индексации поисковых систем, если вы запрещаете URL -адрес в файле robots.txt.
Scuttlebutt между профессионалами SEO и этими ошибками поиска Google заключается в том, что поисковые системы не полностью игнорируют ваш URL, если он указан как запрет и заблокирован в файле robots.txt.
В своих справочных документах Google утверждает, что это нет гарантия Страница не будет проиндексирована, если заблокирована robots.txt.
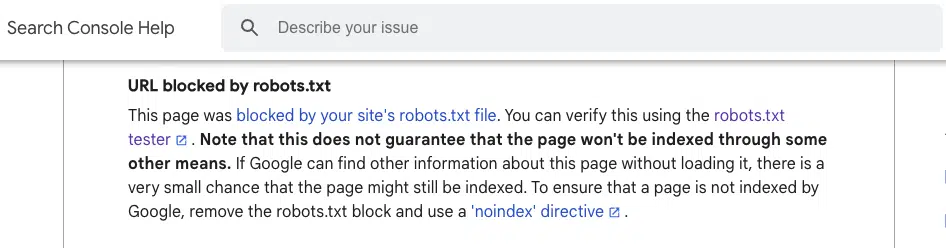
Я видел, как это произошло на веб -сайтах, которыми я управляю, а также с другими профессионалами SEO.
Лили Рэй делится тем, как страницы, заблокированные файлами robots.txt, имеют право на участие появляться в обзорах ИИ со фрагментомПолем
Это только в: Страницы, заблокированные robots.txt, имеют право на появление в обзорах ИИ. С фрагментом. 🙀
Обычно, когда Google обслуживает заблокированные страницы в результатах его поиска, в описании показывает «нет информации для этой страницы».
Но с AIO, очевидно, Google показывает… pic.twitter.com/jrlswwgjh9
— Лили Рэй 😏 (@lilyraynyc) 19 ноября 2024 года
Рэй продолжает показывать Пример от GoodreadsПолем Один URL в настоящее время заблокирован Robots.txt.
Что-то, что я вижу в AIO: кажется, что когда определенный сайт считается хорошим ресурсом по этой теме, этот сайт может получить 3-5 ссылок в AIO.
В этом примере GoodReads имеет 5 различных URL -адресов, упомянутых в ответе (включая один в настоящее время заблокирован Robots.txt 😛) pic.twitter.com/akilxvrk8v
— Лили Рэй 😏 (@lilyraynyc) 19 ноября 2024 года
Патрик Стокс выделил URL, заблокированный robots.txt может быть проиндексирован Если есть ссылки, указывающие на URLПолем
Страницы, заблокированные robots.txt, могут быть проиндексированы и обслуживаются в Google, если у них есть ссылки, указывающие на них.@danielwaisberg Можете ли вы сделать это яснее в предупреждении о живых тестах в GSC? pic.twitter.com/6aybweu8bf
— Патрик Стокс (@patrickstox) 3 февраля 2023 года
Как исправить «заблокирован robots.txt» в консоли поиска Google?
Вручную просмотрите все страницы, помеченные в «Заблокированные robots.txt’Report
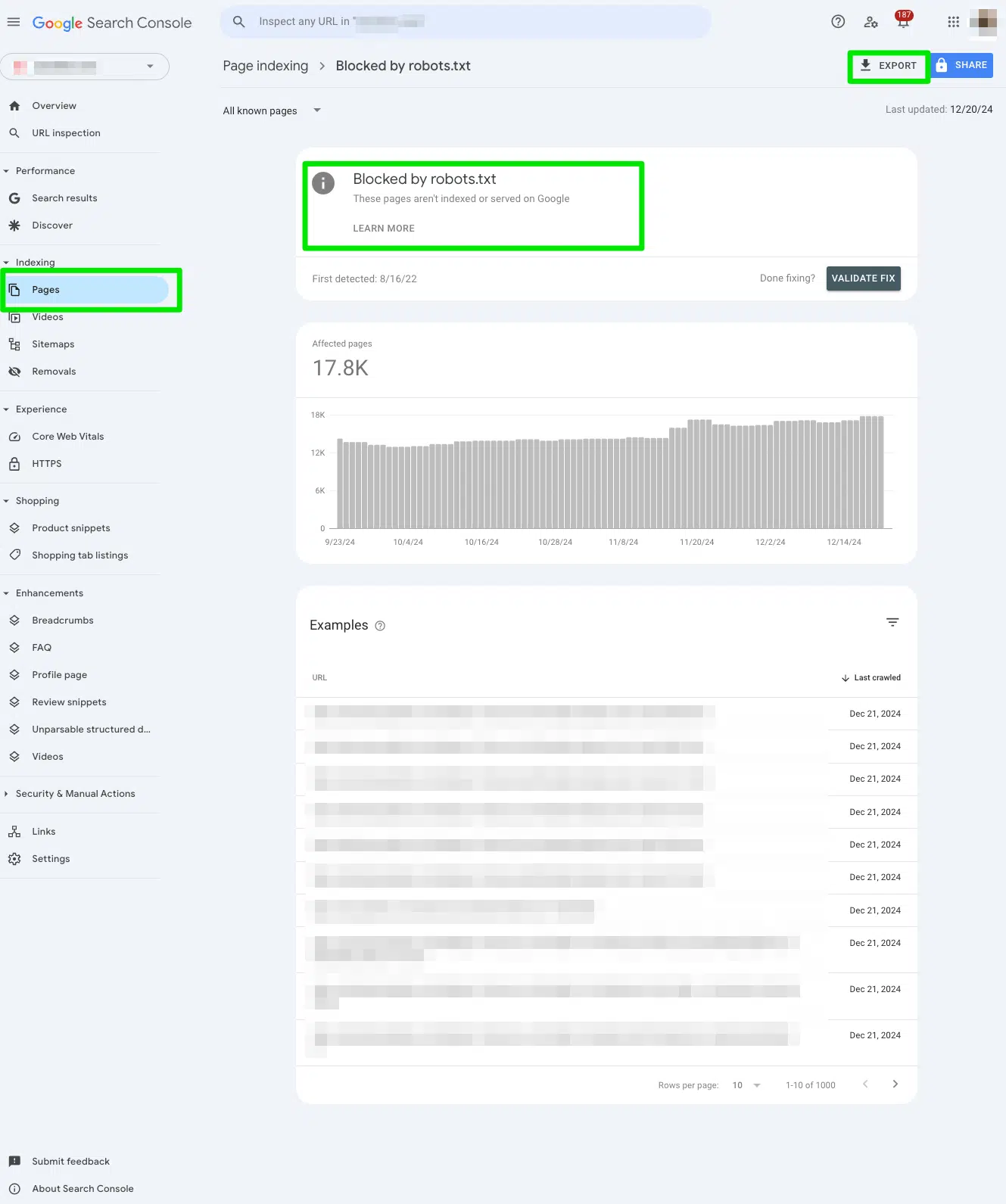
Во -первых, я вручную просмотрел все страницы, помеченные в отчет о поиске Google «Заблокирован Robots.txt».
Чтобы получить доступ к отчету, перейдите к Консоль поиска Google> Страницы> и посмотрите под раздел Заблокирован robots.txt.
Затем экспортируйте данные в Google Sheets, Excel или CSV, чтобы фильтровать их.
Определите, должны ли вы заблокировать URL -адрес из поисковых систем
Сканируйте свой экспортный документ на предмет высокоприоритетных URL-адресов, которые предназначены для просмотра поисковыми системами.
Когда вы видите ошибку, «заблокированную Robots.txt», она говорит Google не ползти URL, потому что вы реализовали директиву DISLAING в файле robots.txt для определенной цели.
Совершенно нормально блокировать URL -адрес от поисковых систем.
Например, вы можете заблокировать страницы благодарности от поисковых систем. Или страницы генерации лидов означали только для продаж.
Ваша цель как профессионала SEO — определить, действительно ли URL -адреса, перечисленные в отчете, должны быть заблокированы и избегаются поисковыми системами.
Если вы намеренно добавили запрет на robots.txt, отчет будет точным, и с вашей стороны не потребуется никаких действий.
Если вы добавили Disloand в robots.txt в аварии, продолжайте читать.
Удалите директиву Diswalling с robots.txt, если вы случайно добавили ее по ошибке
Если вы случайно добавили директиву DISLAING в URL по ошибке, удалите директиву DISLALING вручную из файла robots.txt.
После удаления директивы Dishay из файла robots.txt отправьте URL Осмотрите URL Бар в верхней части консоли поиска Google.
Затем нажмите Запросить индексациюПолем
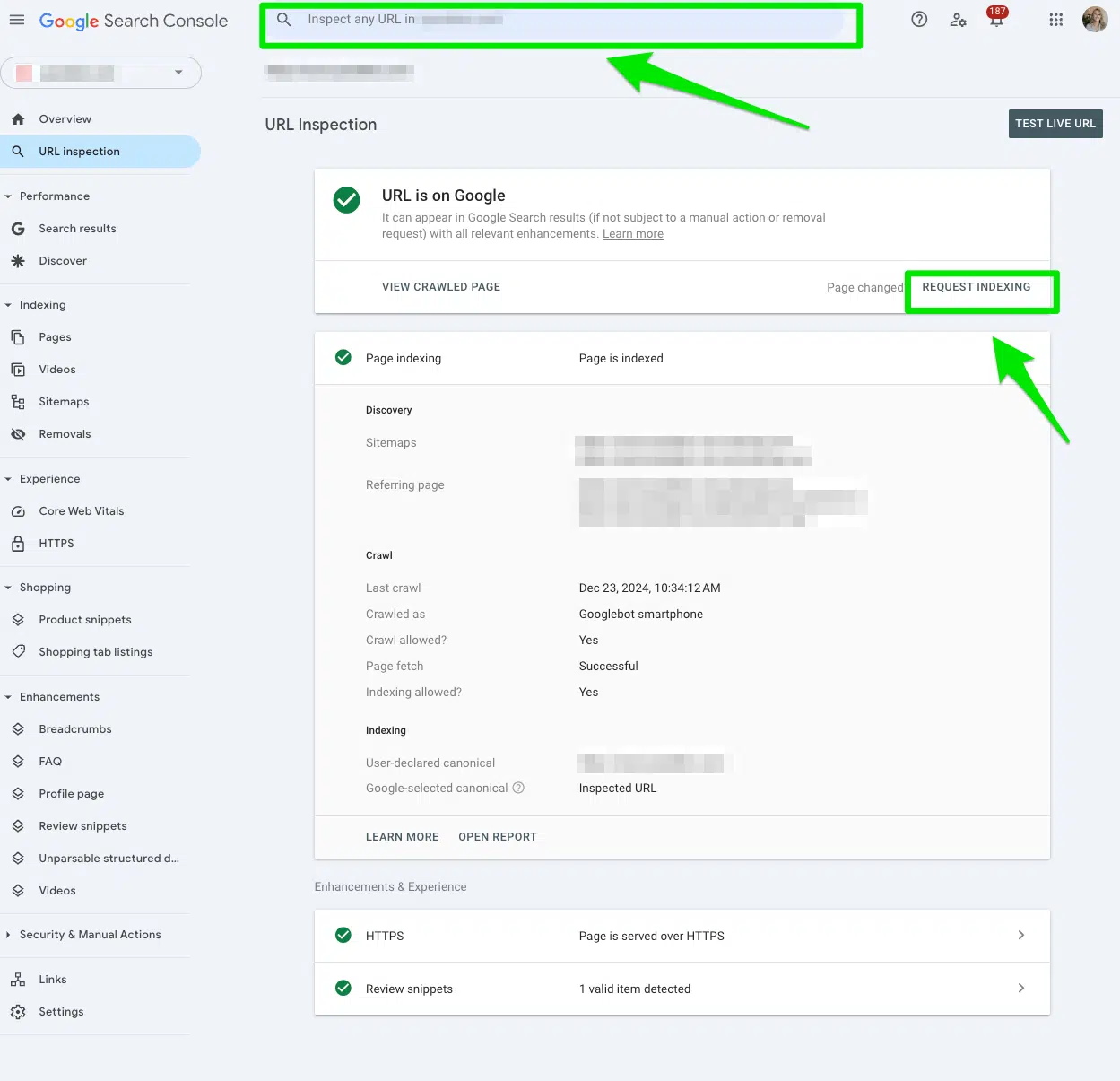
Если у вас есть несколько URL -адресов в целом каталоге, начните с первого URL -адреса каталогов. Это окажет самое большое влияние.
Цель состоит в том, чтобы поисковые системы перестроили эти страницы и снова индексировать URL -адреса.
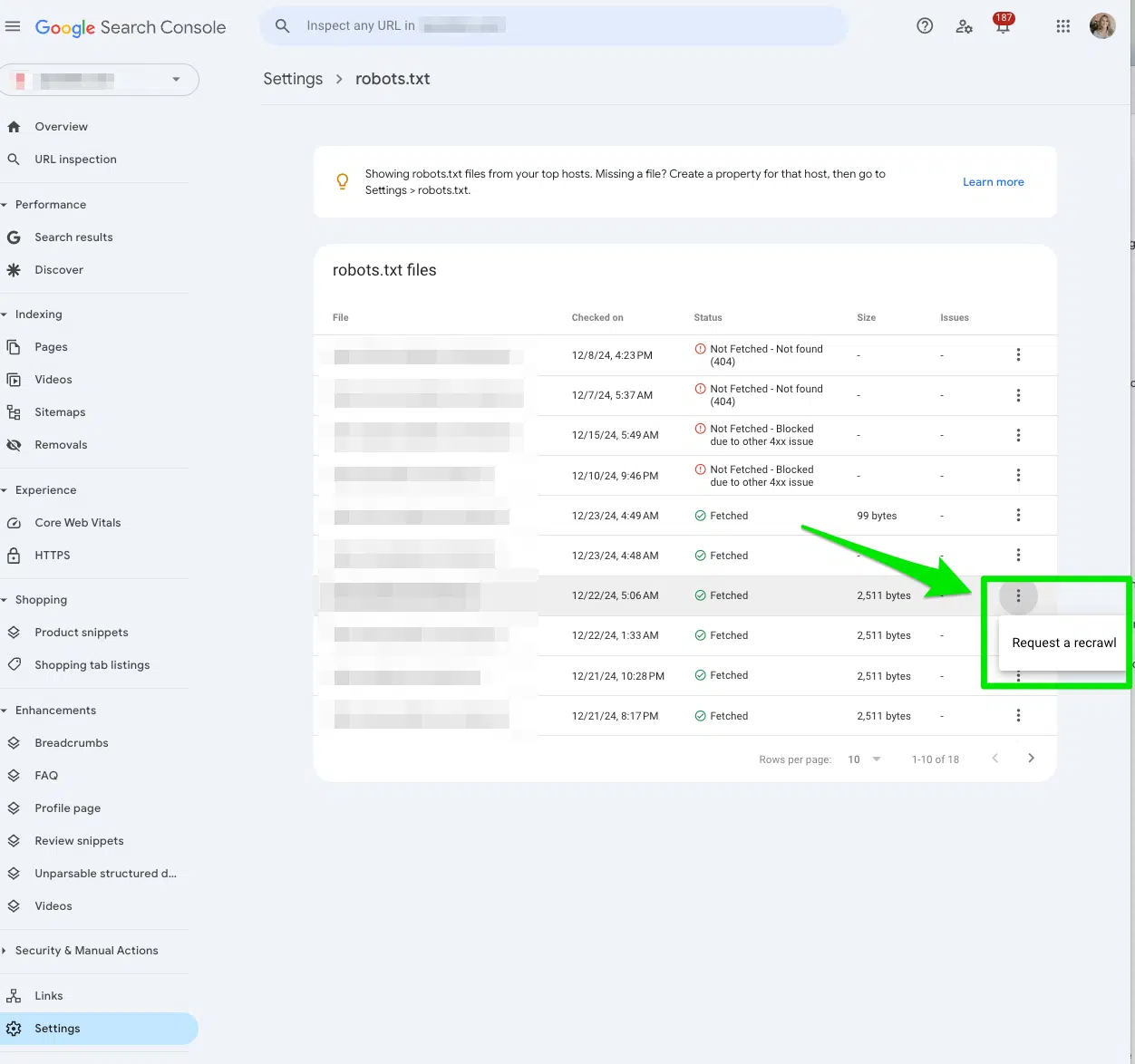
Запрос на то, чтобы решить ваш файл robots.txt
Еще один способ сигнализировать Google, чтобы сканировать ваши случайно запрещенные страницы, — это Запросить репвер в консоли поиска Google.
В поисковой консоли Google перейти к Настройки> robots.txt.
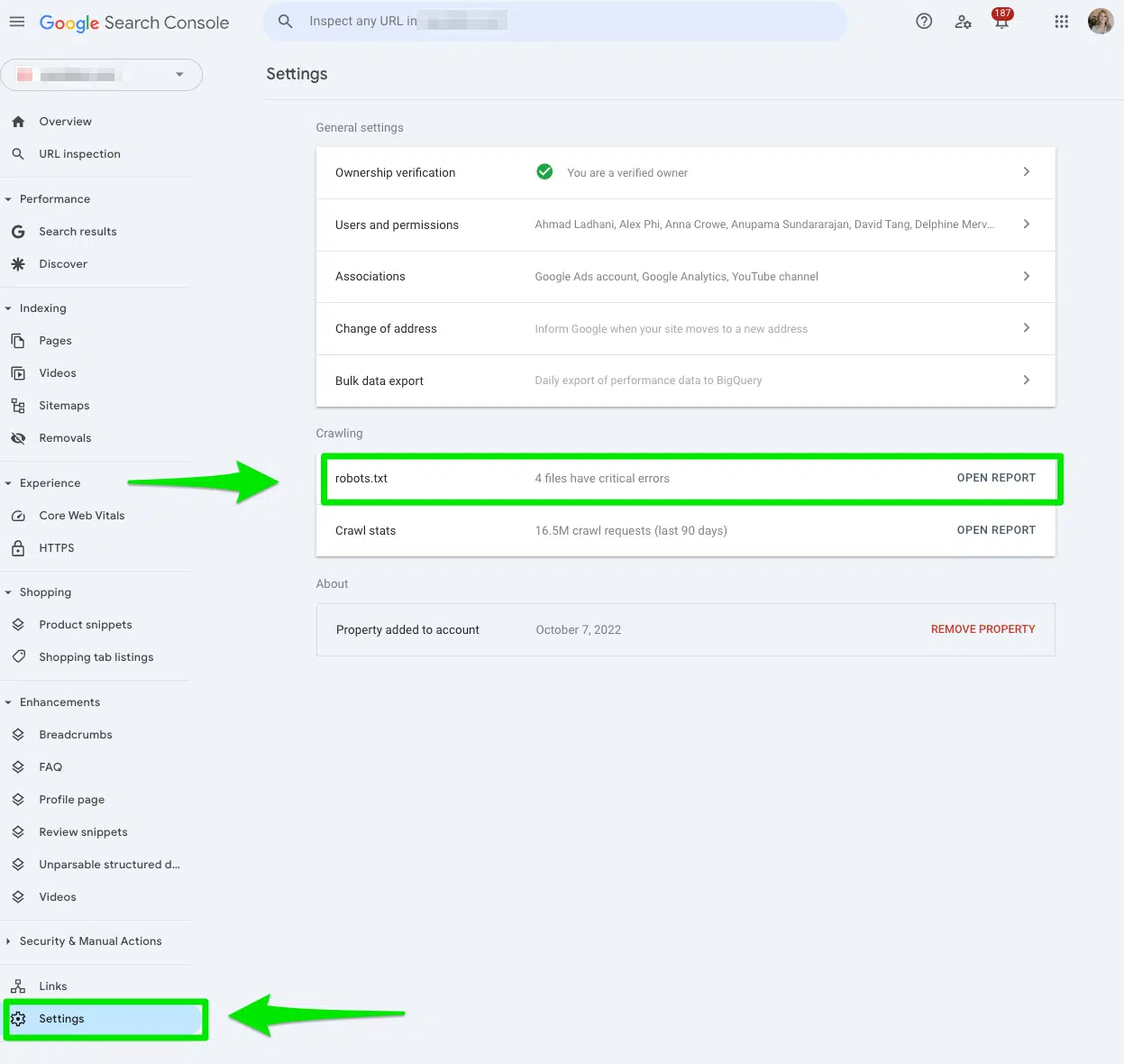
Затем выберите три точки рядом с файлом robots.txt, который вы хотите, чтобы Google решал и выберите Запросить репвер.
Отслеживать производительность до и после
После того, как вы очистите свои директивы File File Robots.txt, и отправили свои URL -адреса, которые будут заменены, используйте машину Wayback, чтобы проверить, когда ваш файл robots.txt был в последний раз обновлен.
Это может дать вам представление о потенциальном воздействии директивы Diswally на конкретный URL.
Затем сообщите о производительности не менее 90 дней после индексации URL.
Получить маркетологи поиска в информационном бюллетене.
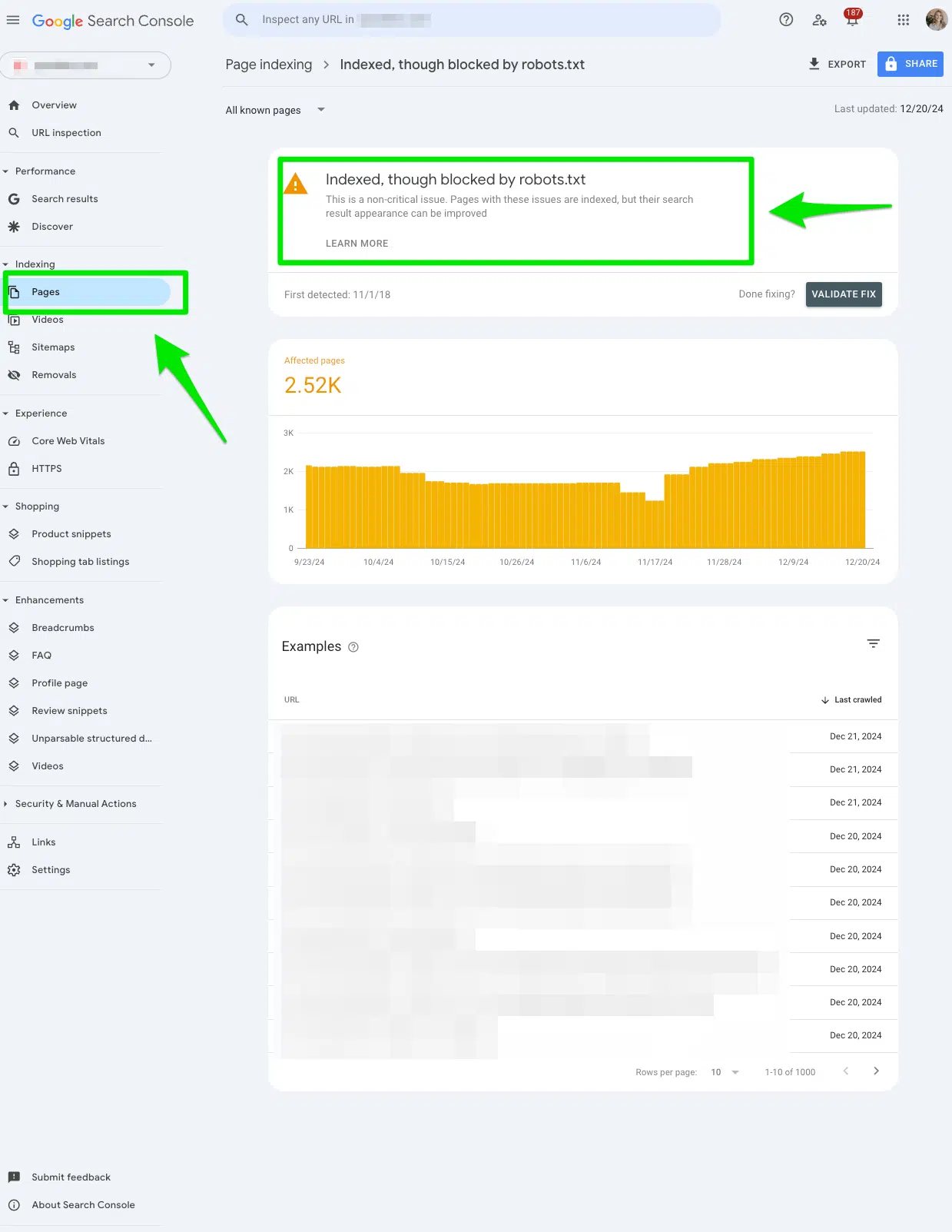
Как исправить «индексированные», хотя и заблокирован Robots.txt ‘в консоли поиска Google?
Вручную просмотрите все страницы, помеченные в «Индексированном, хотя и заблокированном отчету robots.txt ‘
Опять же, запрыгните и вручную просмотрите все страницы, помеченные в консоли поиска Google «Индексированные, хотя и заблокированы отчетом robots.txt».
Чтобы получить доступ к отчету, перейдите в Google Search Консоль> Страницы> и посмотрите под раздел Индексируется, хотя и заблокирован Robots.txt.
Экспортируйте данные, чтобы фильтровать их в Google Sheets, Excel или CSV.
Определите, должны ли вы заблокировать URL -адрес из поисковых систем
Спросите себя:
- Должен ли этот URL -адрес действительно быть проиндексирован?
- Есть ли ценный контент для людей, которые ищут поисковые системы?
Если этот URL должен быть заблокирован поисковыми системами, никаких действий не нужно. Этот отчет действителен.
Если этот URL не предназначен для блокировки поисковыми системами, продолжайте читать.
Удалить Директиву DISLALIN
Если вы ошибочно добавили директиву Dislowing в URL -адрес, удалите директиву DISLALING вручную из файла robots.txt.
После удаления директивы Dishay из файла robots.txt отправьте URL Осмотрите URL Бар в верхней части консоли поиска Google. Затем нажмите Запросить индексациюПолем
Затем, в консоли поиска Google, перейдите к Настройки> robots.txt> Запросить реконвер.
Вы хотите, чтобы Google решил эти страницы, чтобы индексировать URL -адреса и генерировать трафик.
Добавьте тег NoIndex, если вы хотите, чтобы страница была полностью удалена из поисковых систем
Если вы не хотите, чтобы страница была индексирована, рассмотрите возможность добавления тега noIndex вместо использования директивы DISLALING на robots.txt.
Вам все еще нужно удалить Директиву DISLAING с robots.txt.
Если вы сохраните оба, отчет об ошибках «Indexted, хотя и заблокирован Robots.txt» в консоли поиска Google, будет продолжать расти, и вы никогда не решите проблему.
Зачем мне добавлять тег noindex вместо использования директивы Dislower в robots.txt?
Если вы хотите, чтобы URL полностью удален из поисковых систем, вы должны включить тег NoIndex. File Diswalling в файле robots.txt не гарантирует, что страница не будет индексировать.
Файлы robots.txt не используются для управления индексированной. Файлы robots.txt используются для управления ползанием.
Должен ли я включить как тег NoIndex, так и директиву DISLALING на один и тот же URL?
Нет. Если вы используете тег NoIndex на URL, не запрещайте один и тот же URL -адрес в robots.txt.
Вам нужно позволить поисковым системам ползти тег Noindex, чтобы обнаружить его.
Если вы включите один и тот же URL в Директиву DISLALING в файле robots.txt, поисковым системам будет трудно ползти, чтобы определить, что тег NoIndex существует.
Создание четкой стратегии ползания для вашего сайта — это способ избежать ошибок robots.txt в консоли поиска Google
Когда вы видите какой -либо из отчетов об ошибках robots.txt в Spike Google Search Console, у вас может возникнуть соблазн перестать свои позиции, почему вы решили блокировать поисковые системы из определенного URL.
Я имею в виду, не разве URL не может быть заблокирован от поисковых систем?
Да, URL должен и может быть заблокирован от поисковых систем по причине. Не все URL -адреса имеют вдумчивый, привлекательный контент, предназначенный для поисковых систем.
Натуральная, панацея к этому отчету об ошибках в консоли поиска Google всегда для аудита ваших страниц и определения, предназначен ли содержимое для поисковых глаз.
Авторы, способствующие созданию контента, для поисковых земель и выбираются для их опыта и вклада в поисковое сообщество. Наши участники работают под надзором редакционного персонала, а взносы проверены на качество и актуальность для наших читателей. Мнения, которые они выражают, являются их собственными.
