
Есть много чего узнать о намерениях поиска, от использования глубокого обучения до вывода намерений поиска за счет классификации текста и разбивания названий SERP с использованием методов обработки естественного языка (NLP), до кластеризации на основе семантической значимости, с объясненными преимуществами.
Мы не только знаем преимущества расшифровки намерений поиска, но и у нас также есть ряд методов в нашем распоряжении для масштаба и автоматизации.
Итак, зачем нам нужна еще одна статья об автоматизации намерений поиска?
Поиск намерения все еще важнее, когда поиск искусственного интеллекта прибыл.
В то время как больше, как правило, в 10 синих ссылках поиска, противоположность верно для технологии поиска искусственного интеллекта, поскольку эти платформы обычно стремятся минимизировать вычислительные затраты (на провальный фланг), чтобы предоставить услугу.
Содержание
SERP по -прежнему содержат лучшие идеи для поиска
Методы до сих пор включают в себя выполнение вашего собственного ИИ, то есть получение всей копии из названий контента ранжирования для данного ключевого слова, а затем подавать его в модель нейронной сети (которую вы должны затем создать и проверить) или использовать NLP для кластера.
Что если у вас нет времени или знаний, чтобы построить свой собственный ИИ или вызвать открытый AIPI API?
В то время как сходство косинуса рекламировалось как ответ на помощь профессионалам SEO ориентироваться в разграничение тем для таксономии и структур сайта, я все еще утверждаю, что кластеризация поиска по результатам SERP является гораздо более высоким методом.
Это связано с тем, что ИИ очень заинтересован в том, чтобы заземлить свои результаты на SERP и по уважительной причине — он смоделирован на поведении пользователей.
Есть другой способ, который использует собственный ИИ Google, чтобы выполнить работу за вас, без необходимости соскребить весь контент SERPS и создать модель ИИ.
Давайте предположим, что Google оценивает URL -адреса сайта по вероятности того, что контент удовлетворит пользовательский запрос в порядке убывания. Отсюда следует, что если намерение для двух ключевых слов одинаково, то SERP, вероятно, будут похожи.
В течение многих лет многие специалисты SEO сравнивали результаты SERP с ключевыми словами, чтобы вывести общий (или общий) намерение поиска, чтобы оставаться на вершине основных обновлений, так что в этом нет ничего нового.
Добавлено на значение здесь-автоматизация и масштабирование этого сравнения, предлагая как скорость, так и большую точность.
Как кластер ключевые слова с помощью поиска по шкале с помощью Python (с кодом)
Предполагая, что у вас есть ваши SERPS, приведенные к загрузке CSV, давайте импортируем его в ноутбук Python.
1. Импортировать список в ноутбук Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Ниже приведен файл SERPS, теперь импортируемый в DataFrame Pandas.
2. Фильтруйте данные для страницы 1
Мы хотим сравнить результаты Page 1 каждого SERP между ключевыми словами.
Мы разделим DataFrame на Mini Keyword DataFrames, чтобы запустить функцию фильтрации, прежде чем рекомбировать в один рам
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] 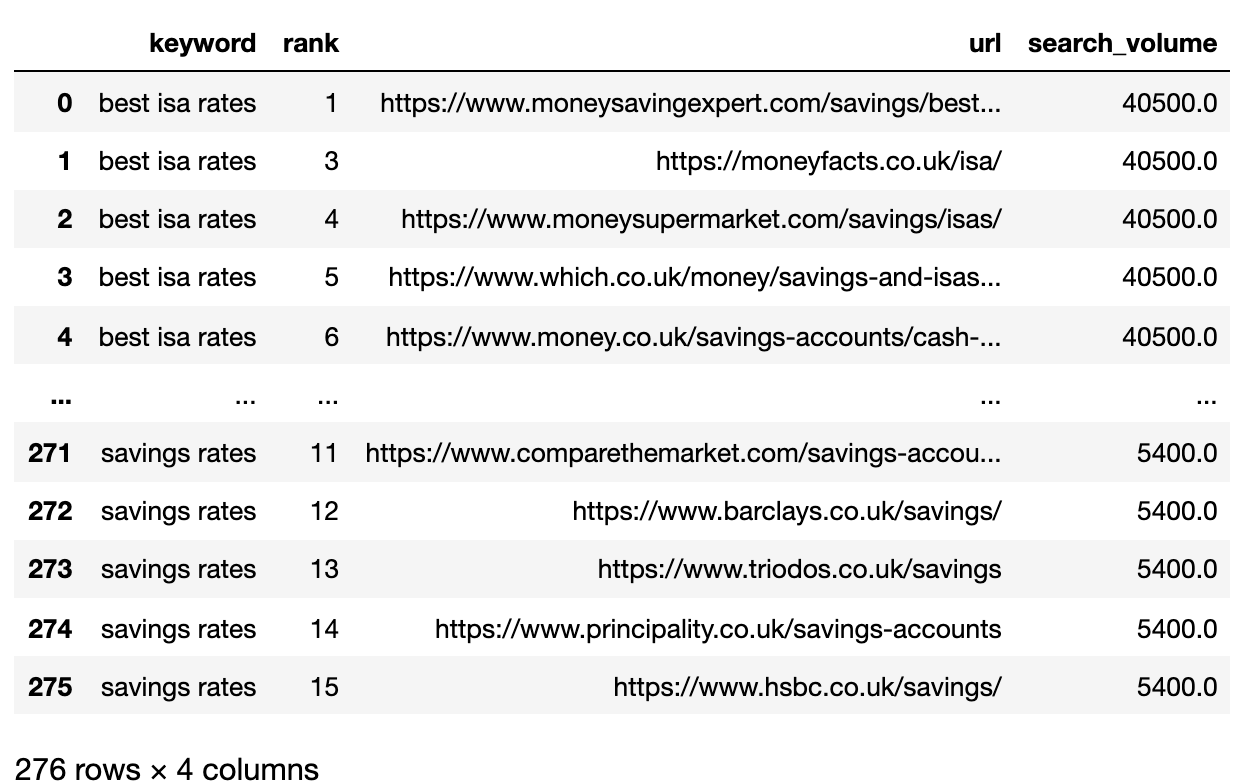 Изображение от автора, апрель 2025 г.
Изображение от автора, апрель 2025 г.3. Convert Ranking URLs To A String
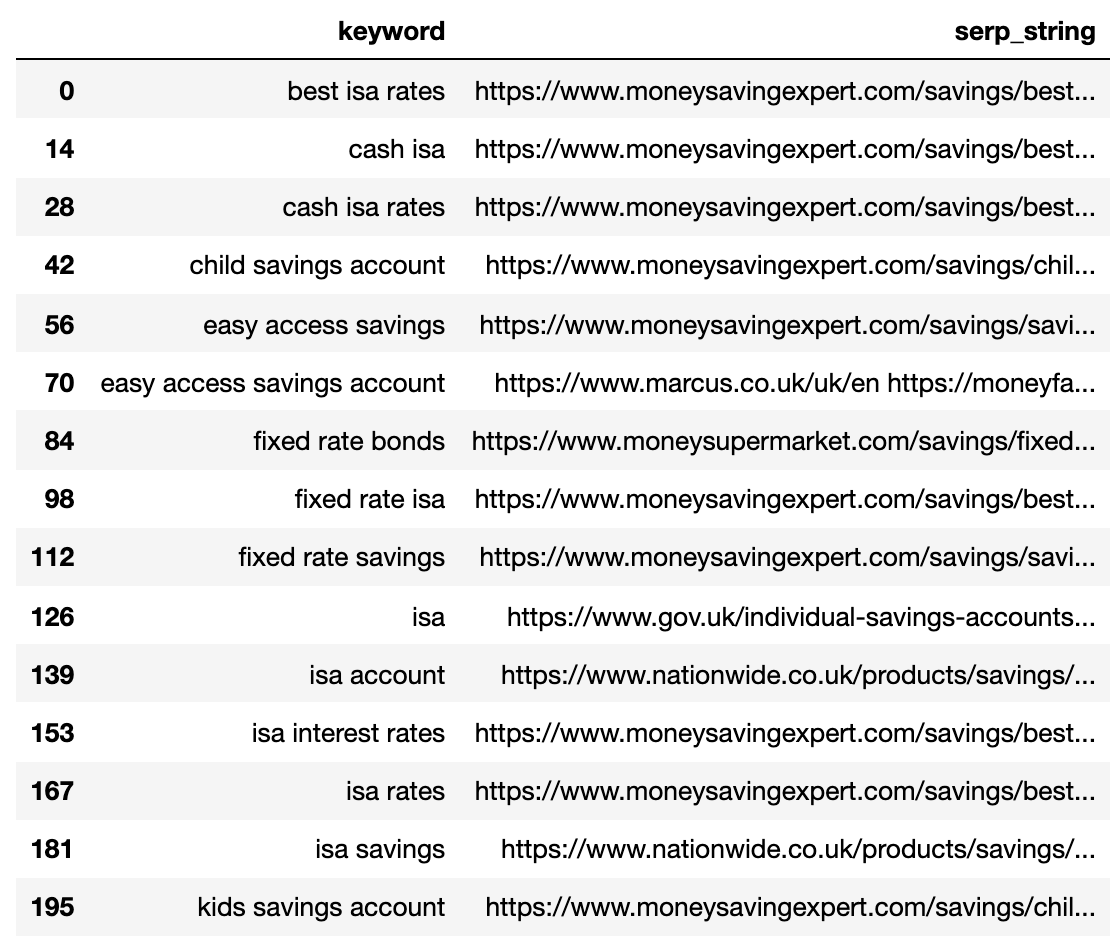
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Ниже показана SERP, сжатая в одну строку для каждого ключевого слова.
 Изображение от автора, апрель 2025 г.
Изображение от автора, апрель 2025 г.4. Сравните расстояние SERP
Чтобы выполнить сравнение, нам теперь нужна каждая комбинация серп -серп -ключевых слов в сочетании с другими парами:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Теперь у нас есть потенциальное название темы, сходство серп -серпсов и объемы поиска каждого.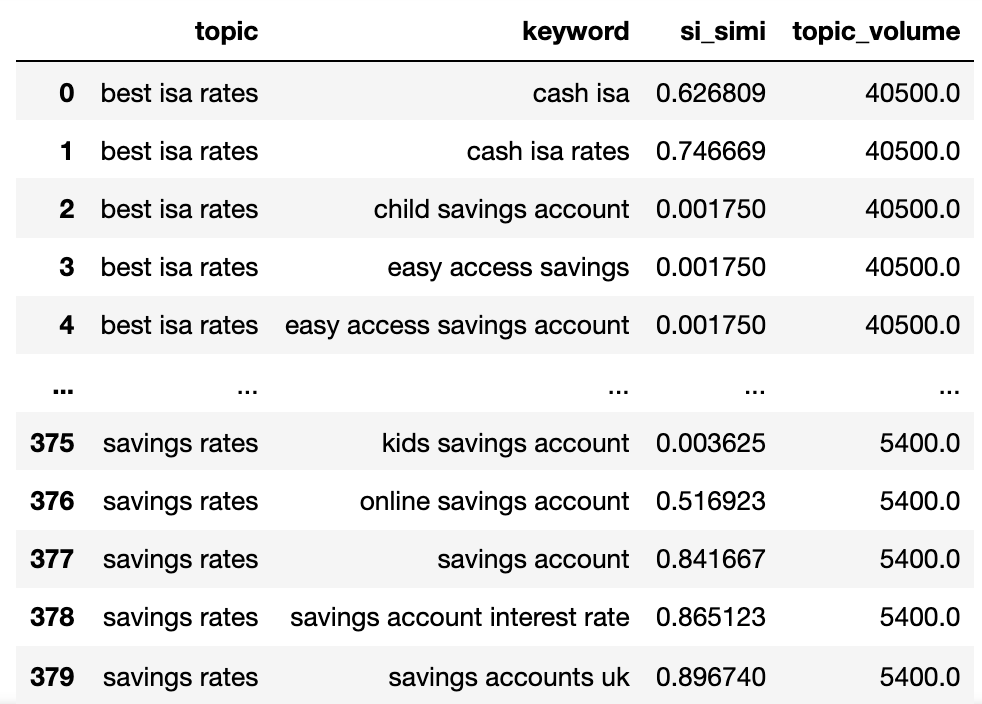
Вы заметите, что ключевое слово и ключевое слово_B были переименованы в тему и ключевое слово соответственно.
Теперь мы собираемся итерации по столбцам в DataFrame, используя метод Lambda.
Техника Lambda является эффективным способом итерации по рядам в DataFrame Pandas, поскольку он преобразует строки в список, в отличие от функции .Iterrows ().
Вот идет:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
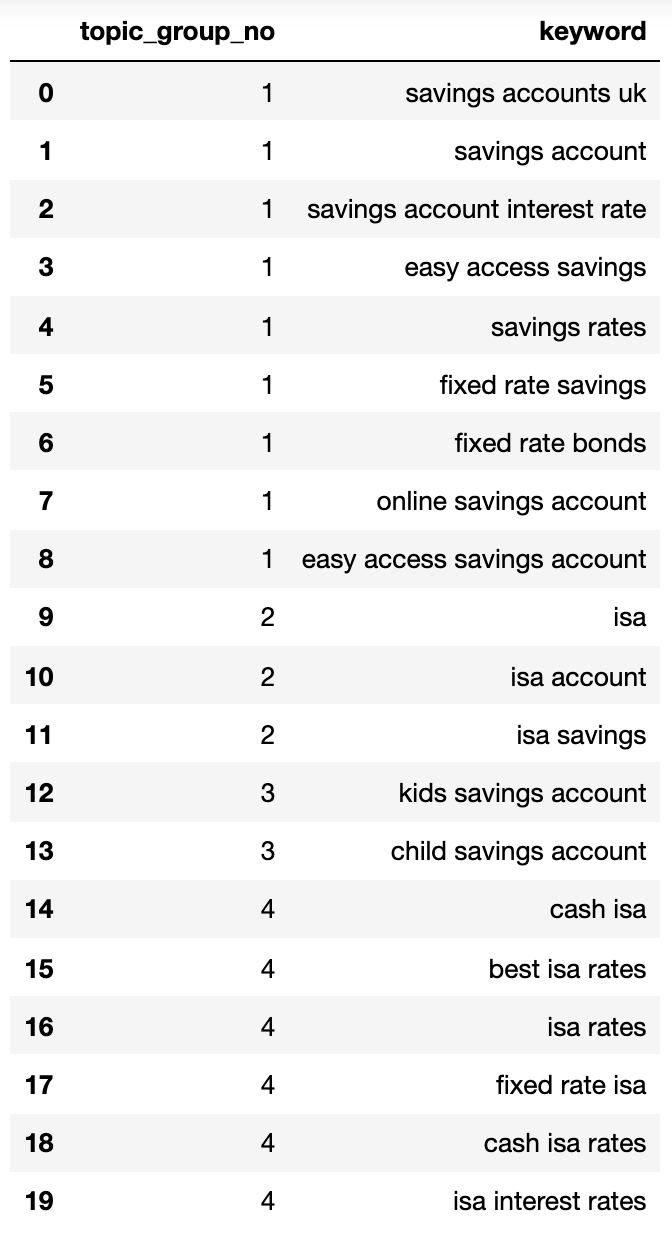
elif len(sim_topic_groups[keyw]) Ниже показан словарь, содержащий все ключевые слова, сгруппированные по намерению поиска в пронумерованные группы:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Давайте внесем это в дата:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
 Изображение от автора, апрель 2025 г.
Изображение от автора, апрель 2025 г.Группы намерения поиска, выше, показывают хорошее приближение к ключевым словам внутри них, чего, вероятно, достигнет эксперта SEO.
Хотя мы использовали только небольшой набор ключевых слов, метод, очевидно, может быть масштабирован до тысяч (если не больше).
Активация выходов, чтобы улучшить поиск
Конечно, вышеупомянутое можно использовать дальше с использованием нейронных сетей, обрабатывая ранжирование контента для более точных кластеров и групповых групп кластеров, как это уже делают некоторые коммерческие продукты.
На данный момент, с этим выводом, вы можете:
- Включите это в свои собственные системы мониторинга SEO, чтобы сделать ваши тенденции, а SEO сообщали более значимыми.
- Создайте лучшие платные поисковые кампании, структурируя свои учетные записи Google Ads, намерение поиска для более высокого качества.
- Слияние избыточных URL -адресов поиска электронной коммерции аспектов.
- Структура таксономия сайта торгового места в соответствии с намерением поиска, а не типичным каталогом продуктов.
Я уверен, что есть больше приложений, о которых я не упомянул — не стесняйтесь комментировать любые важные, которые я еще не упомянул.
В любом случае, ваше исследование ключевых слов SEO только что получило немного более масштабируемое, точное и быстрее!
Скачать Полный код здесь для собственного использованияПолем
Больше ресурсов:
Изображение: Buch и Bee/Shutterstock
