
Есть много чего узнать о намерениях поиска, от использования глубокого обучения для поиска намерения, классифицируя текст и использование названий SERP с использованием методов NLP (естественный язык), вплоть до семантической значимости, с объясненными преимуществами, вплоть до кластеризации, основанной на семантической значимости.
Мы не только знаем преимущества намерения дешифрования, но и ряд методов, доступных для публикации масштабирования и автоматизации.
Так зачем нам нужна еще одна статья об автоматизации намерения поиска?
Поисковые намерения в настоящее время все более важны, потому что поиск искусственного интеллекта прибыл.
Хотя в целом применяется больше в эпохе поиска из 10 синих слева, применяется наоборот с технологией поиска искусственного интеллекта, поскольку эти платформы обычно пытаются минимизировать вычислительные затраты (на провальный фланг), чтобы предоставить услугу.
Содержание
SERP по -прежнему содержат лучшие идеи для поисковых намерений
Предыдущие методы посвящены выполнению вашего собственного ИИ, то есть вставьте все копии из названий ранжирования контента для определенного ключевого слова, а затем вставьте его в модель нейронной сети (которую вы затем должны создавать и проверить) или NLP для кластера.
Что, если у вас нет времени или знаний, чтобы создать свой собственный ИИ или вызвать Open AI -API?
В то время как сходство косинуса в ответ на экспертов SEO по навигации путем разграничения тем по таксономии и структурам местоположения, я все еще утверждаю, что формирование поискового кластера в соответствии с результатами SERP является гораздо более высоким методом.
Это связано с тем, что ИИ очень заинтересован в Земле к земле ее результатов на SERP, и по уважительной причине — оно моделируется в поведении пользователя.
Есть еще один способ, который использует собственный ИИ Google, чтобы выполнить работу за вас, не царапая весь контент SERPS и необходимость создания модели ИИ.
Давайте предположим, что Google связывает URL -адреса сайта через вероятность контента, который выполняет пользовательский запрос в порядке убывания. Отсюда следует, что SERP, вероятно, похожи, если намерение для двух ключевых слов одинаково.
В течение многих лет многие результаты SEO -специалистов SERP для ключевых слов сравнивали, чтобы закрыть общий (или общий) намерение поиска, чтобы поддерживать обновления основных обновлений. Так что это ничего нового.
Создание значений здесь — это автоматизация и масштабирование этого сравнения, которое обеспечивает как скорость, так и большую точность.
Socluster of Keywords для поиска намерений в шкале с Python (с кодом)
Предположим, у вас есть свои SERP для загрузки CSV, мы импортируем его в ваш ноутбук Python.
1. Импортировать список в ноутбук Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Ниже вы найдете файл SERP, который теперь импортируется в кадр данных Pandas.
2. Фильтруйте данные для страницы 1
Мы хотели бы сравнить результаты отдельного SERP между ключевыми словами.
Мы разделим радио -радио на рамки данных Mini -Keyword для выполнения функции фильтра, прежде чем мы перечислены в единый кадр данных, потому что мы хотим отфильтровать на уровне ключевых слов:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] 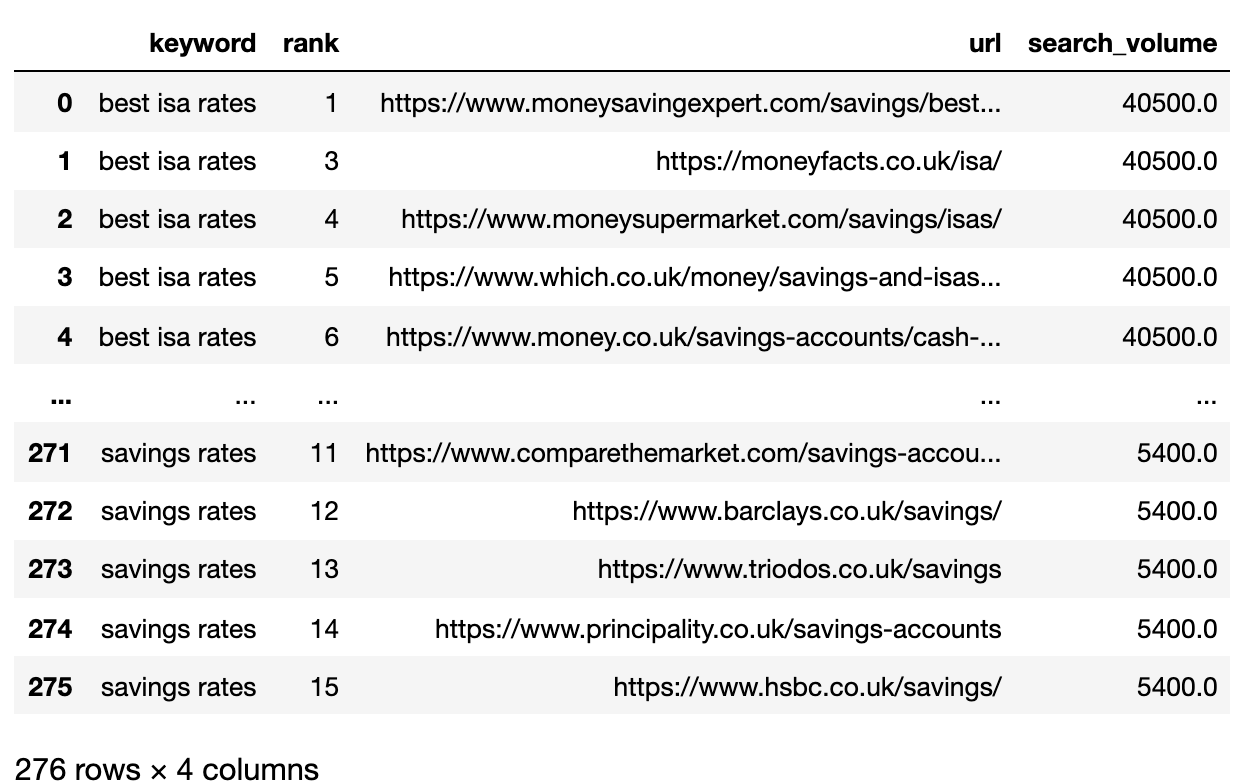 Изображение от автора, апрель 2025 г.
Изображение от автора, апрель 2025 г.3. Convert Ranking URLs To A String
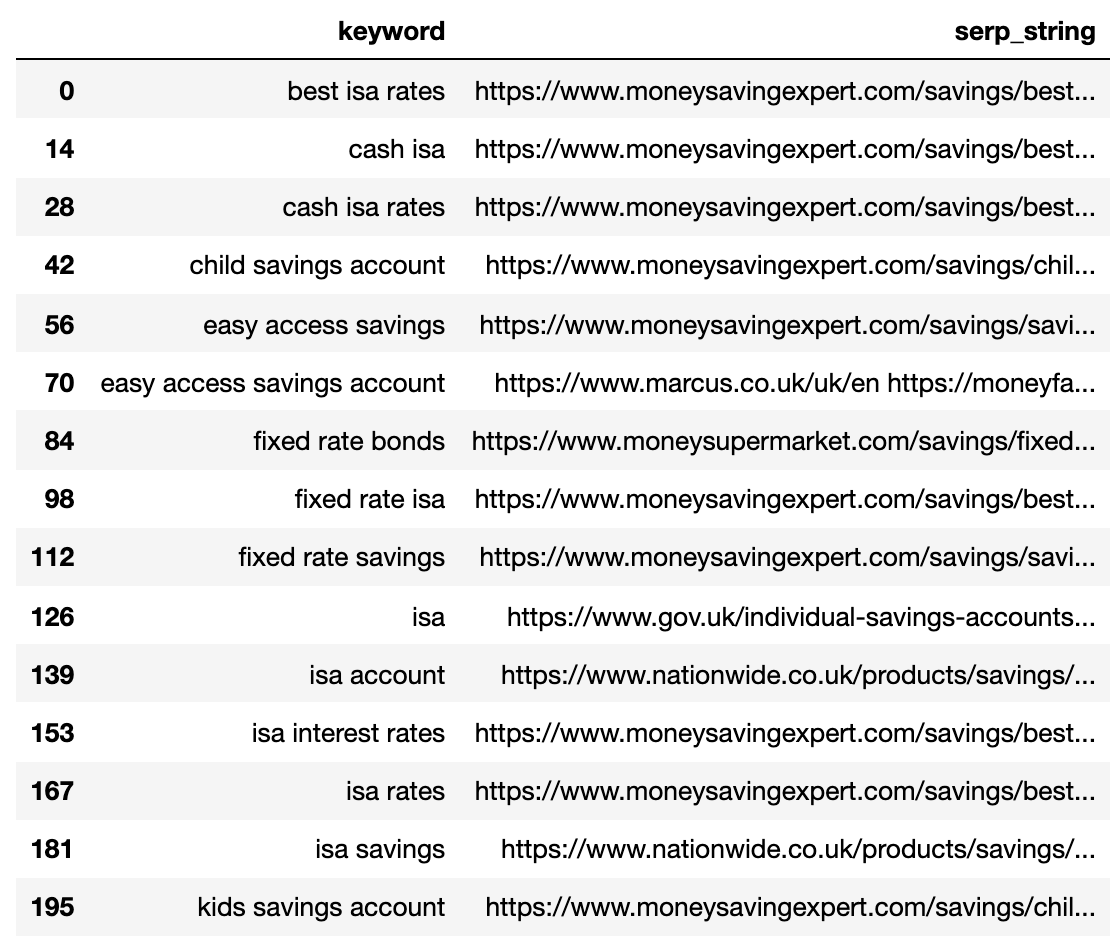
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Ниже приведен SERP для каждого ключевого слова в одной строке.
 Изображение от автора, апрель 2025 г.
Изображение от автора, апрель 2025 г.4. Сравните удаление Serrent
Чтобы провести сравнение, теперь нам нужна каждая комбинация ключевого слова -серпа, в сочетании с другими парами:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Теперь у нас есть потенциальное имя темы, сходство серп -серп и объемы поиска от всех.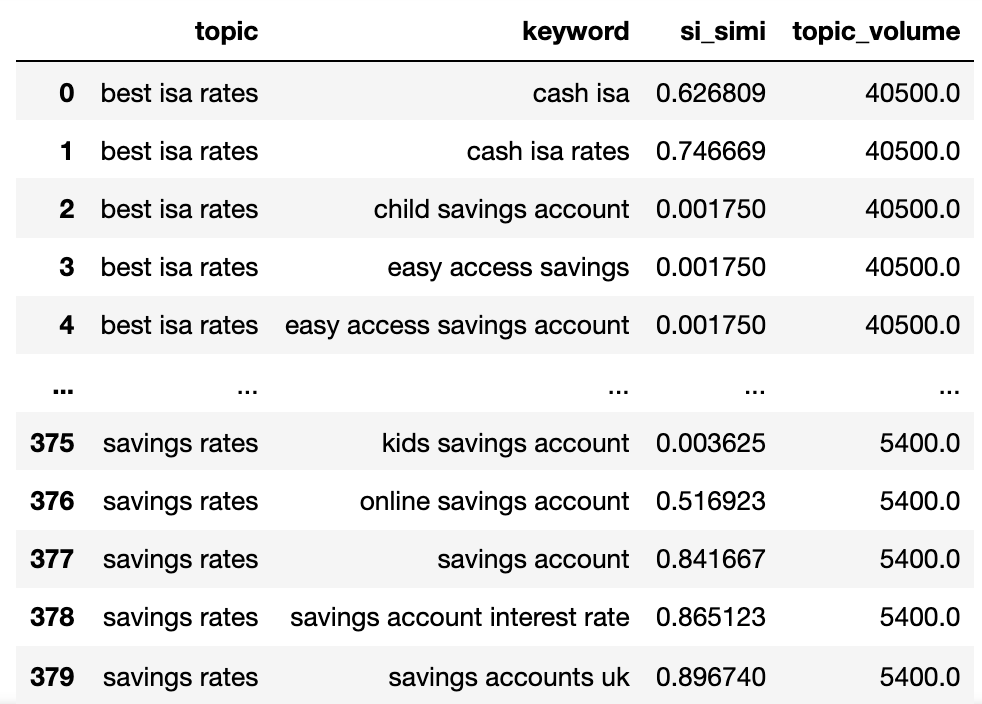
Вы обнаружите, что ключевое слово и ключевое слово_B были переименованы в субъекты или ключевые слова.
Теперь мы работаем с технологией Lambda через столбцы в DataAframe.
Технология Lambda является эффективным способом распределения строк в рамке данных Pandas, поскольку они преобразуют строки в список, в отличие от функции .Iterrows ().
Вот:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
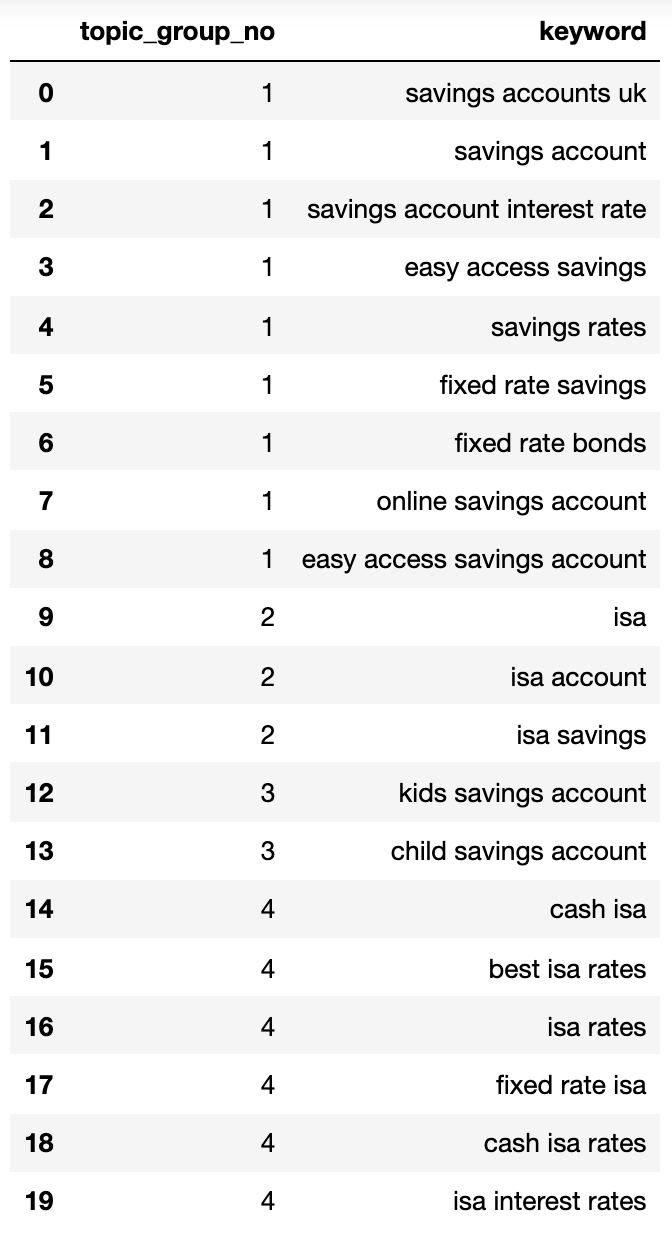
elif len(sim_topic_groups[keyw]) Ниже приведен словарь, который содержит все ключевые слова, которые были записаны в пронумерованных группах с помощью поисковых намерений:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Давайте интегрируем это в кадр данных:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
 Изображение от автора, апрель 2025 г.
Изображение от автора, апрель 2025 г.Приведенные выше намерения поиска показывают хороший подход к ключевым словам в них, чего, вероятно, достигнет эксперта SEO.
Хотя мы использовали только небольшой набор ключевых слов, метод, очевидно, может быть масштабирован до тысяч (если нет).
Активируйте выходы, чтобы улучшить поиск
Конечно, вышеупомянутые с использованием нейронных сетей можно продолжить, что обрабатывает контент ранжирования для более точных кластеров и названий кластерной группы, поскольку некоторые из коммерческих продуктов уже доступны.
На данный момент вы можете использовать эту проблему:
- Интегрируйте это в свои собственные системы мониторинга SEO, чтобы сделать ваши тенденции, а SEO сообщали более значимыми.
- Создайте более платные поисковые кампании, структурируя свои аккаунты Google Ad, поиск более высокой оценки качества.
- Слияние избыточных аспектов -e -commerce -asuch -arls.
- Структура таксономия страницы покупки для поиска намерения вместо типичного каталога продуктов.
Я уверен, что есть больше приложений, о которых я не упомянул. Вы можете комментировать важные вещи, которые я еще не упомянул.
В любом случае, ваш поиск по ключевым словам SEO немного масштабируется, точно и быстрее!
Скачать Полный кода здесь для собственного использованияПолем
Больше ресурсов:
Выбранная картина: книга и пчела/shutterstock
