
Мы, маркетологи, любим хорошую воронку продаж. Это дает ясность относительно того, как работают наши стратегии. У нас есть показатели конверсии, и мы можем отслеживать путь клиента от открытия до конверсии. Но в сегодняшнем мире, где искусственный интеллект стоит на первом месте, наша воронка потемнела.
Мы пока не можем полностью измеряйте видимость в приложениях искусственного интеллекта, таких как ChatGPT или Perplexity. Хотя новые инструменты дают частичную информацию, их данные не являются полными и не всегда надежными. Традиционные показатели, такие как показы и клики, по-прежнему не отражают всей картины в этих областях, в результате чего маркетологи сталкиваются с новым видом пробелов в измерениях.
Чтобы внести ясность, давайте посмотрим, что мы знаем и чего не знаем об измерении ценности структурированных данных (также известных как разметка схемы). Понимая обе стороны, мы можем сосредоточиться на том, что сегодня можно измерить и контролировать, а также на том, какие возможности открываются, поскольку ИИ меняет то, как клиенты находят наши бренды и взаимодействуют с ними.
Содержание
- 1 Почему большая часть данных «видимости искусственного интеллекта» не соответствует действительности
- 2 Что такое видимость при поиске ИИ?
- 3 Известное: что мы можем уверенно измерить для структурированных данных
- 4 Неизвестное: то, что мы пока не можем измерить
- 5 За пределами SEO на уровне страницы: построение графиков знаний
- 6 Реализованная концепция семантической сети
- 7 Превращение темной воронки в интеллектуальную
Почему большая часть данных «видимости искусственного интеллекта» не соответствует действительности
ИИ породил потребность в показателях. Маркетологи, отчаянно пытаясь количественно оценить, что происходит на вершине воронки, обращаются к волне новых инструментов. Многие из этих платформ создают новые показатели, такие как «авторитет бренда на платформах искусственного интеллекта», которые не основаны на репрезентативных данных.
Например, некоторые инструменты пытаются измерить «подсказки ИИ», рассматривая короткие ключевые фразы так, как если бы они были эквивалентны потребительским запросам в ChatGPT или Perplexity. Но такой подход вводит в заблуждение. Потребители пишут более длинные, насыщенные контекстом подсказки, которые выходят далеко за рамки того, что предполагают показатели на основе ключевых слов. Эти подсказки содержат множество нюансов, диалоговые и высоко персонализированные – они не имеют ничего общего с традиционными длинными запросами.
Эти синтетические показатели дают ложный комфорт. Они отвлекают от того, что на самом деле можно измерить и контролировать. Дело в том, что ChatGPT, Perplexity и даже обзоры искусственного интеллекта Google не предоставляют нам четких и полных данных о видимости.
Итак, что же мы можем измерить, что действительно влияет на видимость? Структурированные данные.
Что такое видимость при поиске ИИ?
Прежде чем углубляться в метрики, стоит определить «видимость поиска ИИ». В традиционном SEO видимость означала появление на первой странице результатов поиска или получение кликов. В мире, управляемом искусственным интеллектом, видимость означает, что вас понимают, доверяют и на нее ссылаются как поисковые системы, так и системы искусственного интеллекта. Структурированные данные играют важную роль в этой эволюции. Это помогает определить, связать и уточнить цифровые сущности вашего бренда, чтобы поисковые системы и системы искусственного интеллекта могли их понять.
Известное: что мы можем уверенно измерить для структурированных данных
Давайте поговорим о том, что сегодня известно и измеримо применительно к структурированным данным.
Увеличение рейтинга кликов благодаря расширенным результатам
Из данных нашего ежеквартального бизнес-обзора мы видим, что за счет внедрения структурированных данных на странице контент обеспечивает богатый результат, а корпоративные бренды постоянно наблюдают увеличение рейтинга кликов. В настоящее время Google поддерживает более 30 типов богатые результатыкоторые продолжают появляться в органическом поиске.
Например, согласно нашим внутренним данным, в третьем квартале 2025 года у одного корпоративного бренда в отрасли бытовой техники рейтинг кликов на страницах товаров увеличился на 300 %, когда был присвоен расширенный результат. Богатые результаты по-прежнему обеспечивают как видимость, так и рост конверсий в органическом поиске.
Увеличение количества кликов, не связанных с брендом, благодаря надежным связям с объектами
Важно различать базовую разметку схемы и надежную разметку схемы со связыванием сущностей, в результате чего образуется граф знаний. Разметка схемы описывает то, что находится на странице. Связывание сущностей соединяет эти вещи с другими четко определенными сущностями на вашем сайте и в Интернете, создавая отношения, которые определяют значение и контекст.
Сущность — это уникальная и различимая вещь или концепция, например человек, продукт или услуга. Связывание сущностей определяет, как эти сущности связаны друг с другом, либо через внешние авторитетные источники, такие как Викиданные и граф знаний Google, либо через ваш собственный внутренний график знаний контента.
Например, представьте себе страницу о враче. Разметка схемы будет описывать врача. Надежный, семантический разметка также будет связана с Викиданными и графиком знаний Google, чтобы определить их специальность, а также ссылаться на больницы и медицинские услуги, которые они предоставляют.
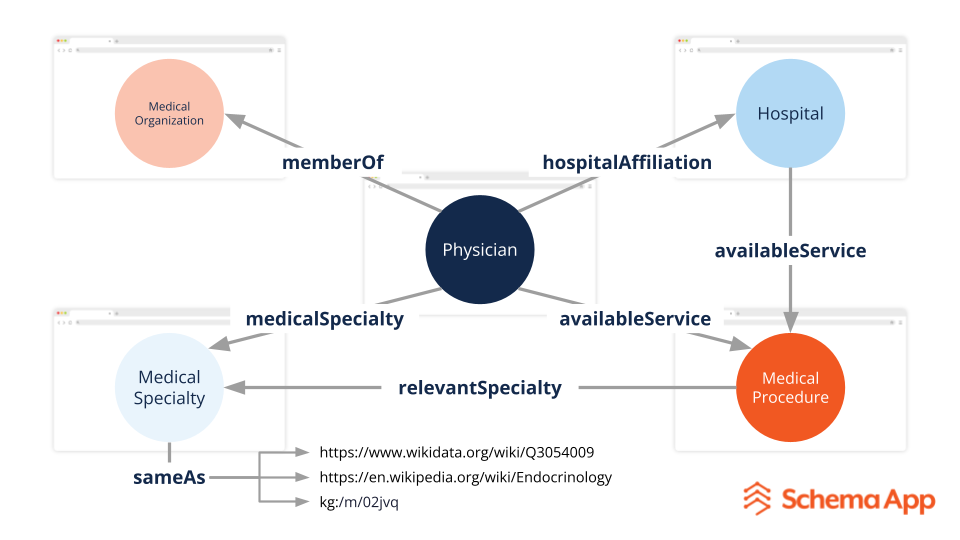 Изображение автора, ноябрь 2025 г.
Изображение автора, ноябрь 2025 г.Видимость AIO
Традиционные SEO-метрики пока не могут напрямую измерять работу ИИ, но некоторые платформы могут идентифицировать некоторые случаи, когда бренд упоминается в результатах обзора ИИ (AIO).
Исследование отчета BrightEdge показало, что внедрение практик SEO на основе сущностей способствует повышению видимости ИИ. В отчете отмечалось:
«ИИ отдает приоритет контенту от известных, надежных организаций. Перестаньте оптимизировать фрагментированные ключевые слова и начните формировать всесторонний авторитет темы. Наши данные показывают, что авторитетный контент в три раза чаще цитируется в ответах ИИ, чем узконаправленные страницы».
Неизвестное: то, что мы пока не можем измерить
Хотя мы можем измерить влияние сущностей в разметке схемы с помощью существующих показателей SEO, у нас пока нет прямого представления о том, как эти элементы влияют на производительность модели большого языка (LLM).
Как LLM используют разметку схемы
Видимость начинается с понимания, а понимание начинается со структурированных данных.
Доказательств этого становится все больше. В сообщении в блоге Microsoft от 8 октября 2025 г.: «Оптимизация вашего контента для включения в ответы поиска AI (Microsoft Advertising», Кришна Мадхавенглавный менеджер по продукту Microsoft Bing, написал:
«Для маркетологов задача состоит в том, чтобы их контент был прост для понимания и структурирован таким образом, чтобы его могли использовать системы искусственного интеллекта».
Он добавил:
«Схема — это тип кода, который помогает поисковым системам и системам искусственного интеллекта понимать ваш контент».
Аналогично, Google статья«Основные способы обеспечить эффективную работу вашего контента с помощью искусственного интеллекта Google в поиске» подтверждает это: «структурированные данные полезен для обмена информацией о вашем контенте в машиночитаемом виде».
Почему Google и Microsoft делают упор на структурированные данные? Одной из причин может быть стоимость и эффективность. Структурированные данные помогают создавать графики знаний, которые служат основой для более точного, объяснимого и заслуживающего доверия ИИ. Исследования показали, что графики знаний могут уменьшить галлюцинации и улучшить успеваемость в LLM:
Хотя сама разметка схемы обычно не используется непосредственно для обучения LLM, фаза извлечения в системах генерации с расширенным поиском (RAG) играет решающую роль в том, как LLM реагируют на запросы. В недавней работе GraphRAG от Microsoft Система генерирует граф знаний (посредством извлечения сущностей и отношений) из текстовых данных и использует этот график в своем конвейере поиска. В их экспериментах GraphRAG часто превосходит базовый подход RAG, особенно для задач, требующих многошагового рассуждения или обоснования между разрозненными объектами.
Это помогает объяснить, почему такие компании, как Google и Microsoft, поощряют корпоративные бренды инвестировать в структурированные данные — это соединительная ткань, которая помогает системам искусственного интеллекта получать точную контекстуальную информацию.
За пределами SEO на уровне страницы: построение графиков знаний
Существует важное различие между оптимизацией одной страницы для SEO и построением графика знаний, который связывает контент всего вашего предприятия. В недавнем интервью Вместе с Робби Стейном, вице-президентом по продуктам Google, было отмечено, что запросы ИИ могут включать в себя десятки скрытых подзапросов (известное как разветвление запроса). Это предполагает уровень сложности, который требует более целостного подхода.
Чтобы добиться успеха в этой среде, брендам необходимо выйти за рамки оптимизации страниц и вместо этого построить графики знаний или, скорее, уровень данных, который представляет полный контекст их бизнеса.
Реализованная концепция семантической сети
Что действительно интересно, так это то, что концепция семантической сети уже здесь. Как писали Тим Бернерс-Ли, Ора Лассила и Джеймс Хендлер в «Семантическая сеть» (Scientific American, 2001).:
«Семантическая сеть позволит машинам понимать семантические документы и данные, а также позволит программным агентам перемещаться со страницы на страницу для выполнения сложных задач для пользователей».
Мы наблюдаем, как это происходит сегодня: транзакции и запросы происходят непосредственно в системах искусственного интеллекта, таких как ChatGPT. Microsoft уже готовится к следующему этапу, который часто называют «агентской сетью». В ноябре 2024 года Р.В. Гуха – создатель Схема.орг и теперь в Microsoft – анонсировали открытый проект под названием НЛВеб. Цель NLWeb — стать «самым быстрым и простым способом эффективно превратить ваш веб-сайт в приложение искусственного интеллекта, позволяющее пользователям запрашивать содержимое сайта, используя естественный язык, точно так же, как с помощью помощника искусственного интеллекта или второго пилота».
В недавнем разговоре с Гухой он поделился, что цель NLWeb — стать конечной точкой взаимодействия агентов с веб-сайтами. Для этого NLWeb будет использовать структурированные данные:
«NLWeb использует полуструктурированные форматы, такие как Schema.org… для создания интерфейсов на естественном языке, которые могут использовать как люди, так и агенты искусственного интеллекта».
Превращение темной воронки в интеллектуальную
Точно так же, как нам не хватает реальных показателей для измерения эффективности бренда в ChatGPT и Perplexity, у нас также пока нет полных показателей роли разметки схемы в видимости ИИ. Но у нас есть четкие и последовательные сигналы от Google и Microsoft о том, что их опыт искусственного интеллекта частично использует структурированные данные для понимания контента.
Будущее маркетинга принадлежит брендам, которые понимаются машинами и которым доверяют. Структурированные данные являются одним из факторов, способствующих этому.
Дополнительные ресурсы:
Рекомендованное изображение: Роман Самборский/Shutterstock
