
Как поисковые системы индексируют сайты в 2023 году?
Как меняются подходы к оптимизации индексации сайта?
Давайте рассмотрим важные нюансы индексации сайта поисковыми системами, о которых мало кто знает.
Содержание
Влияние индексации веб-сайта на рейтинг в поисковых системах
Оптимизация индекса – отправная точка при начале работы по продвижению сайта.
Большое количество мусора создает проблему, поскольку удалить из индекса большое количество страниц крайне сложно.
Бан в файле robots.txt решает проблему только для Яндекса. Google потребует дополнительного сканирования страниц, которые будут исключены из поисковой системы.
Инструментов для массового удаления страниц из индекса Google не существует. Официальный инструмент лишь скрывает страницы из результатов поиска.
Как индекс влияет на рейтинг? Влияние происходит следующим образом:
- Наличие большого количества сайтов с тонкий контент или бесполезный контент воспринимается как попытка манипуляции;
- От Принимающие факторы сайт.
Вот что показывает практика Удаление страниц с бесполезным контентом из индекса положительно влияет на позиции сайта в результатах поиска.
Как индексируются сайты?
Во-первых, давайте разберемся с этим термином. Что такое индексирование сайта? Индексация сайта – сканирование, сохранение страниц в базе данных поисковой системы и дальнейшая их обработка алгоритмами.
Процесс индексации сайта в упрощенном виде:
- Поисковый робот сканирует веб-сайт;
- Система индексирования обрабатывает контент.
На практике схема индексации гораздо сложнее. Давайте посмотрим, как работает процесс индексации, на примере Google.
В процессе индексирования участвуют три отдельные системы: планировщик, сканер сайта и система обработки.
Планировщик Google создает план индексации с учетом краулингового бюджета веб-сайта.
Робот Googlebot сканирует веб-сайты и сохраняет данные в двоичной форме.
Гугл кофеин — система обработки индексируемых страниц. Задача системы — получать, обрабатывать и распределять страницы сайта по индексам.
Каждую секунду Caffeine параллельно обрабатывает сотни тысяч страниц. Процесс индексации еще не завершен. Индекс будет обновляться частями.
Что происходит с кофеином?
Вот как работает Google Caffeine
Весь процесс системы индексации:
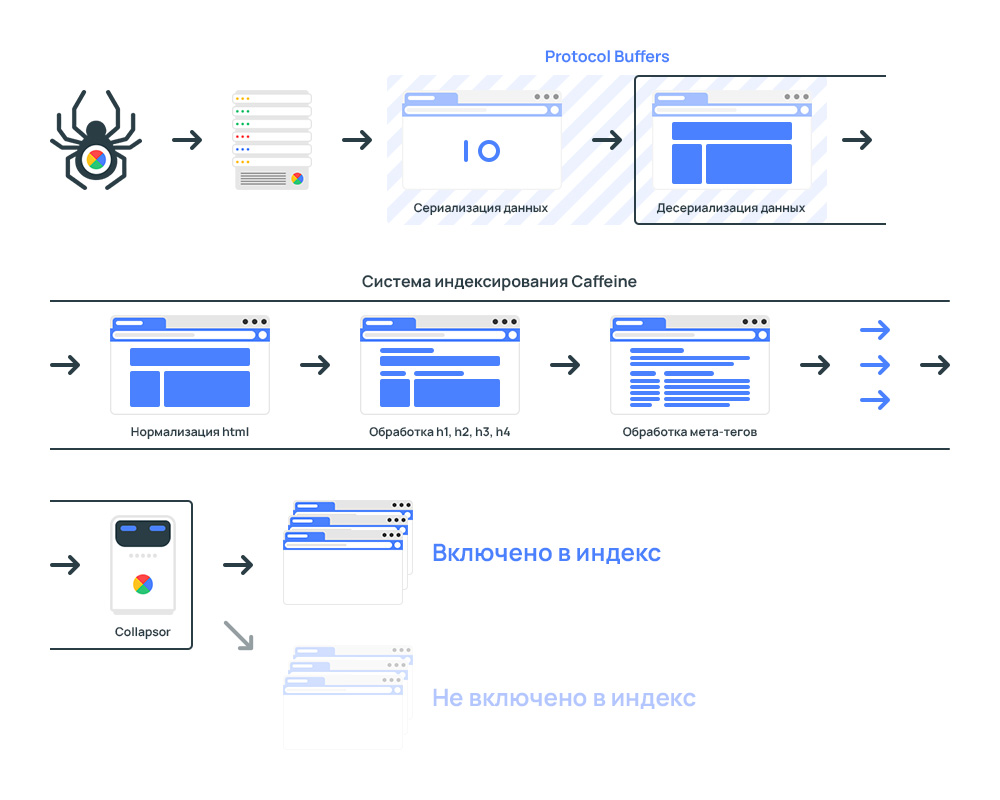
Сначала загружаются данные, собранные поисковым роботом Googlebot.
Из соображений скорости обработки данные передаются в двоичная формато есть применяется процесс преобразования структуры данных в последовательность байтов.
Он используется для обработки данных Буфер протокола.
Протокол Buffers — это протокол сериализации (передачи) структурированных данных, предложенный Google как эффективная двоичная альтернатива текстовому формату XML.
После получения данных система индексирования преобразует данные в специальный формат, который могут анализировать роботы.
Страница отправляется в лексер. Цель лексера — найти и исправить ошибки в коде страницы.
Ошибки кода часто встречаются на веб-сайтах. Технически невозможно проанализировать содержимое некорректных страниц.
Чтобы исключить ошибки, код анализируется лексером HTML и автоматически исправляется.
Ошибки в верстке страницы не оказывают прямого влияния на ранжирование.
Пример Лексера — HTML-валидатор W3C.
Далее идет нормализация данных. Страницы разделены на фрагменты. Например:
- Мета-теги
- заголовок
- Н1, ч2, ч3, ч4, ч5
- Другой
На заключительном этапе система включается. Свернуть.
Google Collapsor в системе индексации сайта
Свернуть является подсистемой в системе индексирования.
Редьюсер определяет, куда переместить страницу. Параметры:
- Индекс страниц, которые проиндексированы, но бесполезны;
- Индекс обслуживания или индекс обслуживания.
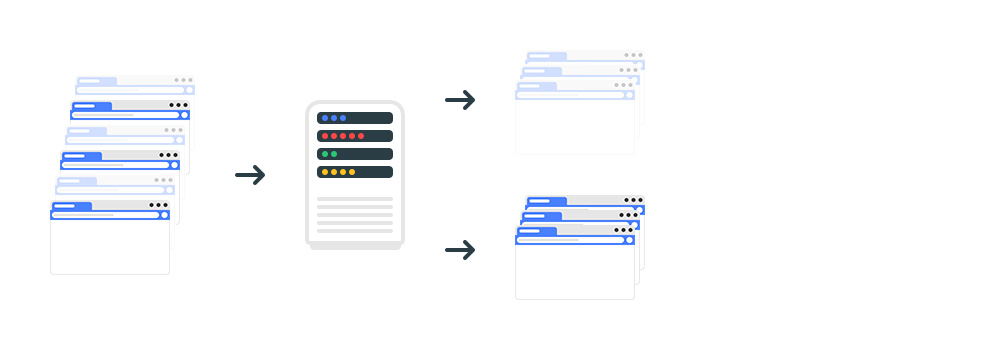
Это коллапс, который присваивает статус страницам. мягкий 404.
Коллапс фильтрует индекс бесполезных страниц: отсутствующие товары, дубликаты, технические страницы и т.д.
Как обнаруживаются дубликаты страниц? Анализируя контрольную сумму каждой страницы на основе слов на странице. То есть, если есть две страницы с одинаковой контрольной суммой, анализатор считает их дубликатами.
Индексирование сайта гарантирует только обработку страницы. Включение страниц в результаты поиска зависит от того, как Google Collapser оценивает страницы.
Результаты поиска генерируются на основе индекса обслуживания.
Индекс обслуживания Google – Индекс обслуживания
Индекс обслуживания или индекс обслуживания — основной индекс поисковой системы, состоящий из страниц, участвующих в ранжировании.
Расположены в отдельных центрах обработки данных, откуда пользователи получают результаты поиска.
Документ попадает в индекс обслуживания, если:
- код ответа – 200;
- Запрета на индексацию нет;
- Collapsor пропустил страницу в индексе.
Поисковая система обрабатывает коды ответов следующим образом:
- 200. Робот должен объехать сбоку;
- 3ХХ. Робот должен обойти страницу, которая открывается через редирект.
- 4ХХ и 5ХХ. Страница с таким кодом не должна включаться в поиск. Если страница была размещена в результатах поиска до того, как с ней связался робот, она будет удалена из индекса.
Как проверить наличие страниц в индексе? Давайте посмотрим на пример страницы indexoid.com.
Проверка индексации сайта в Яндексе с учетом всех поддоменов сайта:
site:indexoid.com
Проверка индексации в Яндексе по разделам:
url:chrome.google.com/*
Проверка индексации сайта в Google с учетом всех поддоменов сайта:
site:wixfy.com
Проверьте индексацию по разделам:
url:chrome.google.com/*
С учетом записей в шапках:
site:ru.megaindex.com intitle:yandex
Проверьте индексацию по разделам:
inurl:chrome.google.com/*
Если страницы больше не открываются, эти страницы необходимо удалить из индекса.
Если сайт вернет код ошибки, страницы будут удалены из индекса.
Уязвимость может быть использована конкурентами в поисковой системе.

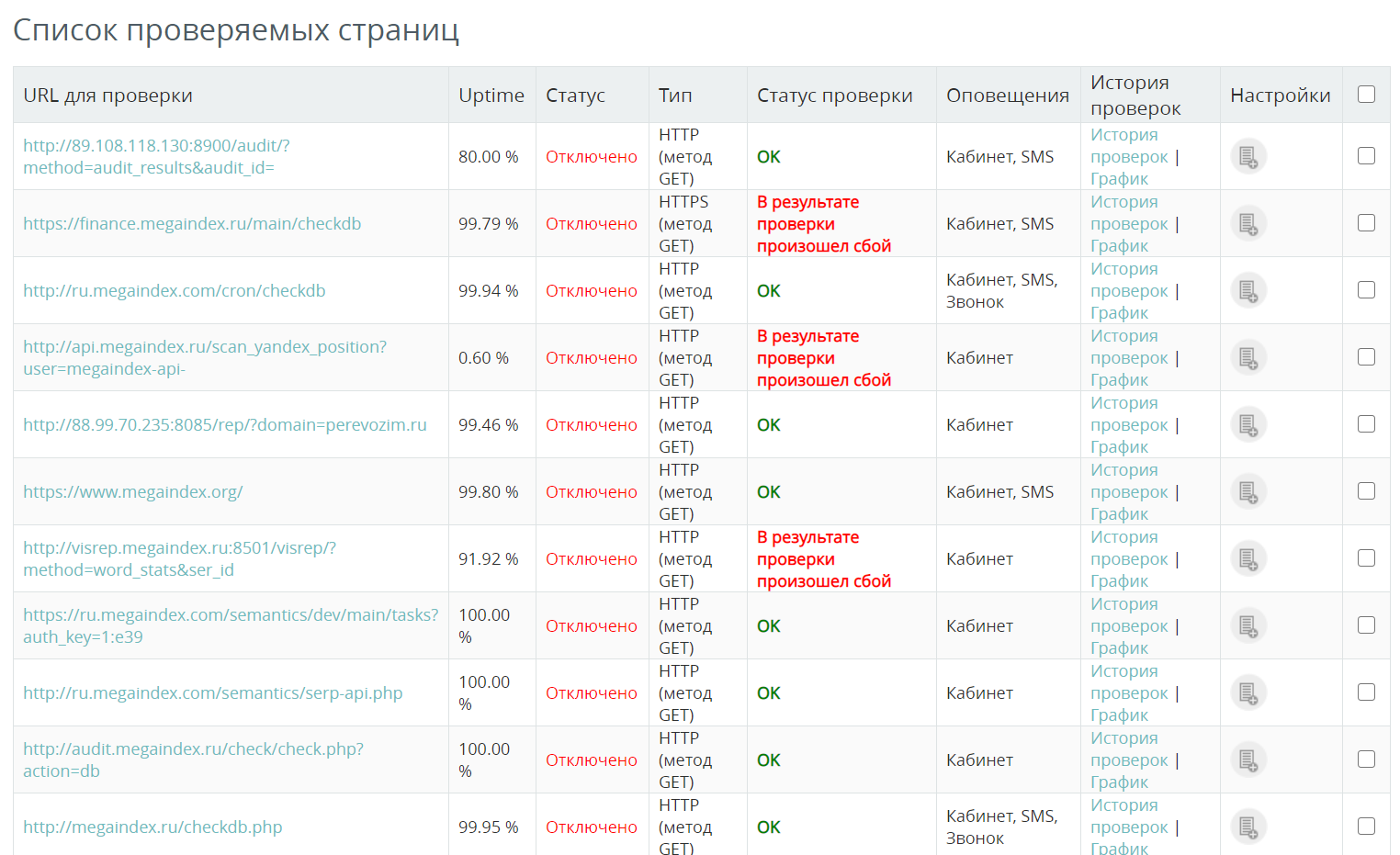
Как я могу проверить доступность сайта? Например, вы можете воспользоваться сервисом MegaIndex. Стоимость 1 чека составляет 0,01 руб. Если сервер сайта перестанет работать, система уведомит вас об инциденте удобным способом.
Ссылка на сервис – проверьте доступность сайта.
Пример отчета:
вопросы и ответы
От чего зависит количество индексируемых страниц?
Максимальное количество страниц, которые будут проиндексированы при следующем сканировании веб-сайта роботом, определяется показателем, называемым бюджетом сканирования.
Значение рассчитывается планировщиком сканирования.
Подробности раскрыты в материале – Краулинг-бюджет сайта – что это такое и как его оптимизировать?
Как меняются подходы к оптимизации индексов?
Подходы к оптимизации индекса сайта на самом деле меняются. Например, если раньше наличие большого количества страниц в результатах поиска положительно влияло на рекламу, то сегодня ситуация иная.
Большое количество страниц в индексе позволило сформировать значительный статический ссылочный вес на сайте. Сигнал передавался по ссылкам на важные внутренние страницы. Это улучшило рейтинг важных страниц.
Но алгоритмы поисковых систем улучшились. Эта тактика уже не была эффективной. Наличие большого количества страниц на веб-сайте имеет смысл только в том случае, если страницы способны генерировать трафик.
Выводы
Задача улучшения индексации сайта требует внимания, поскольку от этого зависит позиция сайта в результатах поиска.
Даже страницы, закрытые в robots.txt, могут влиять на рейтинг с помощью сигналов Web Vitals.
Для индексации должны быть открыты следующие страницы:
- Страницы, предназначенные для привлечения трафика из результатов поиска;
- Страницы веб-сайта, важные для EAT.
Страницы сайта могут быть проиндексированы, однако они игнорируются при включении в индекс службы.
Предоставленная информация является достоверной и подтвержденный из официальных источников.
Другие поисковые системы имеют аналогичный процесс индексации.
Если вы хотите узнать, как найти бесполезные страницы на сайте и удалить страницы из индекса поисковых систем, пишите в комментариях.
Если у вас есть вопросы по теме, пишите в комментариях.
