
Продолжая свой первый анализ более 546 000 обзоров ИИ, я углубился в три вопроса:
- Как связаны общие данные сканирования и обзоры ИИ?
- Как намерение пользователя меняет обзоры ИИ?
- Как распределяются первые 20 позиций доменов, которые ранжируются в органическом поиске и цитируются в AIO?
Содержание
Как связаны данные общего сканирования и обзоры ИИ?
Включение обычного сканирования не влияет на видимость AIO так сильно, как чистый органический трафик.
Common Crawl — некоммерческая организация, которая сканирует Интернет и предоставляет данные бесплатно. Это крупнейший источник данных для обучения генеративного ИИ.
Некоторые сайты, такие как Blogspot, публикуют гораздо больше страниц, чем другие, что поднимает вопрос о том, дает ли это им преимущество при получении ответов на вопросы LLM.
Результат: Я задавался вопросом, будут ли сайты, которые предоставляют больше страниц, чем другие, также иметь большую видимость в AI Overviews. Это оказалось неправдой.
Я сравнил 500 лучших доменов по вкладу страниц в Common Crawl с 30 000 лучших доменов в моем наборе данных и обнаружил слабую корреляцию 0,179.
Причина в том, что Google, вероятно, не полагается на Common Crawl для обучения и информирования AI Overviews, а использует свой собственный индекс.
Затем я проанализировал взаимосвязь между 3000 доменов с наибольшим органическим трафиком из Semrush и 30 000 доменов в моем наборе данных и обнаружил сильную взаимосвязь, равную 0,714.
Другими словами, домены, которые получают большой органический трафик, имеют большую вероятность оказаться очень заметными в обзорах AI.
AIO, похоже, все больше поощряет то, что работает в органическом поиске, но некоторые критерии все еще очень разрозненны.
Важно отметить, что некоторые сайты искажают эту взаимосвязь.
Если отфильтровать Wikipedia и YouTube, то корреляция снижается до 0,485 — все еще высокая, но ниже, чем у двух гигантов.
Корреляция не меняется при исключении более крупных сайтов, что подтверждает тот факт, что действия, которые работают в органическом поиске, оказывают большое влияние на обзоры ИИ.
Как я написал в своей предыдущий пост:
Более высокий рейтинг в результатах поиска, безусловно, увеличивает шансы быть заметным в AIO, но это далеко не единственный фактор.
В результате компании могут исключить бота Common Crawl из robots.txt, если они не хотят появляться в общедоступных наборах данных (и в ИИ-системах, таких как Chat GPT), и при этом оставаться заметными в обзорах ИИ Google.
Как намерение пользователя меняет обзоры ИИ?
Намерение пользователя формирует форму и содержание AIO.
В своем предыдущем анализе я пришел к выводу, что точное совпадение запроса не имеет особого значения:
Данные показывают, что только 6% AIO содержат поисковый запрос.
Это число немного выше в SGE, на 7%, и ниже в живых AIO, на 5,1%. В результате, удовлетворение намерений пользователя в контенте гораздо важнее, чем мы могли бы предположить. Это не должно вызывать удивления, поскольку намерение пользователя уже много лет является ключевым требованием к ранжированию в SEO, но увиденные данные шокируют.
Расчет точного (доминирующего) намерения пользователя для всех 546 000 запросов потребовал бы чрезвычайно больших вычислительных ресурсов, поэтому я рассмотрел общие абстракции: информационную, локальную и транзакционную.
Абстракции менее полезны при оптимизации контента, но они хороши при анализе совокупных данных.
Я сгруппировал:
- Информационные запросы с использованием вопросительных слов, таких как «что», «почему», «когда» и т. д.
- Транзакционные запросы с такими терминами, как «купить», «загрузить», «заказать» и т. д.
- Локальные запросы по типу «рядом», «близко» или «рядом со мной».
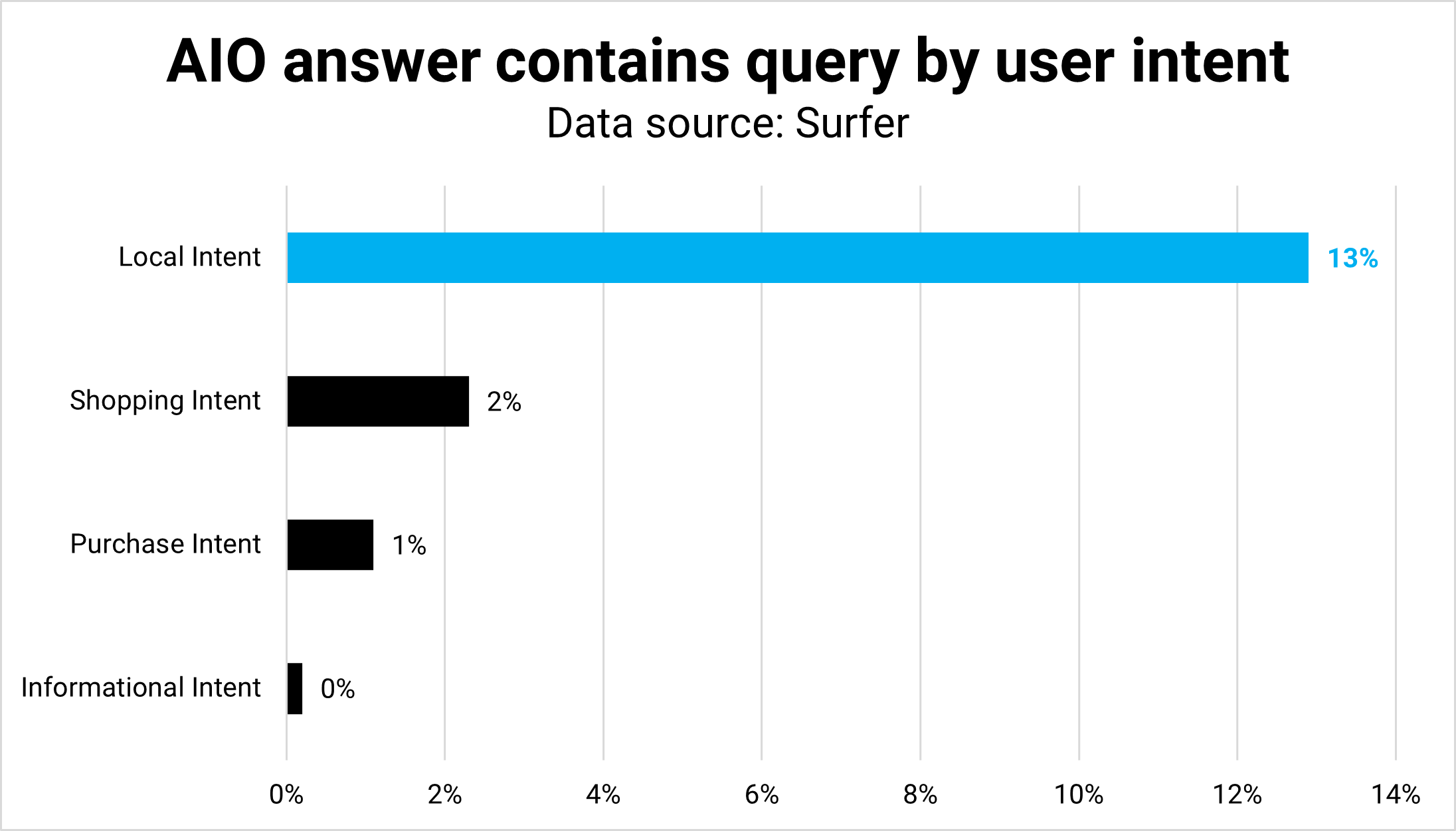 Кредит изображения: Кевин Индиг
Кредит изображения: Кевин ИндигРезультат: Различия в намерениях пользователей отражаются в форме и функции. Средняя длина (количество слов) почти одинакова для всех намерений, за исключением локального, что имеет смысл, поскольку пользователи хотят список местоположений вместо текста.
Аналогично, торговые предложения AIO часто представляют собой списки товаров с небольшим контекстом, если только это не вопросы, связанные с покупками.
Наибольшее количество совпадений между запросом и ответом наблюдается в локальных запросах; наименьшее — в информационных запросах.
Понять и удовлетворить намерения пользователей в вопросах сложнее, но и важнее, чтобы они были видны в AIO, чем, например, в избранных фрагментах.
Как распределяются 20 лучших органических позиций?
В своем последнем анализе я обнаружил, что почти 60% URL-адресов, которые появляются в результатах поиска AIO и органического поиска, не попадают в первые 20 позиций.
Для этой записки я разбил первую двадцатку на более мелкие части, чтобы понять, склонны ли AIO чаще ссылаться на URL-адреса, находящиеся на более высоких позициях, или нет.
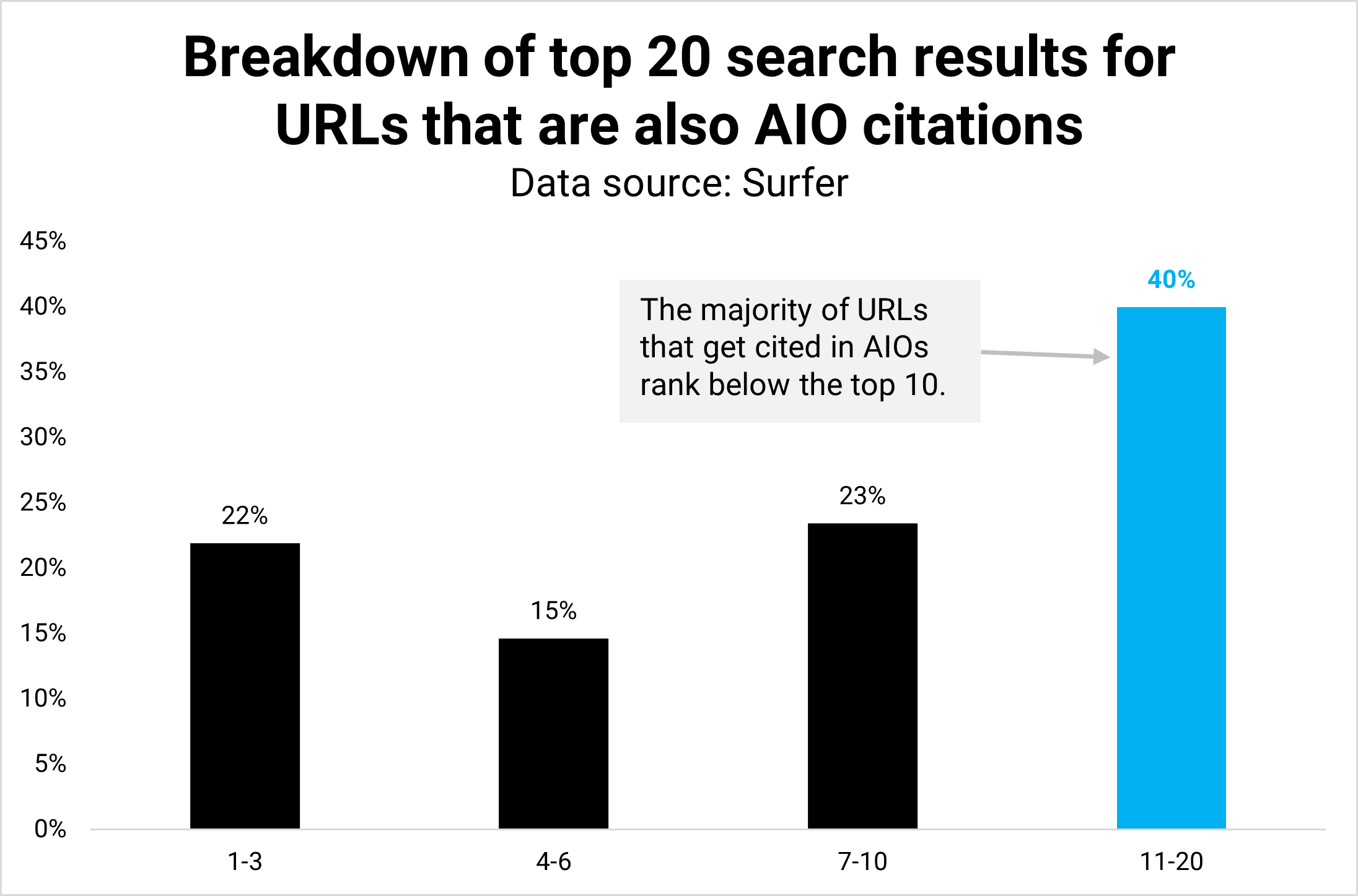 Кредит изображения: Кевин Индиг
Кредит изображения: Кевин ИндигРезультат: Оказывается, 40% URL-адресов в AIO занимают позиции 11–20, и только половина (21,9%) входят в тройку лучших.
Большинство (60%) URL-адресов, цитируемых в AIO, по-прежнему ранжируются на первой странице органических результатов, что подтверждает тот факт, что более высокий органический рейтинг, как правило, приводит к более высоким шансам быть цитируемым в AIO.
Однако данные также показывают, что присутствовать в AIO с более низким органическим рейтингом практически невозможно.
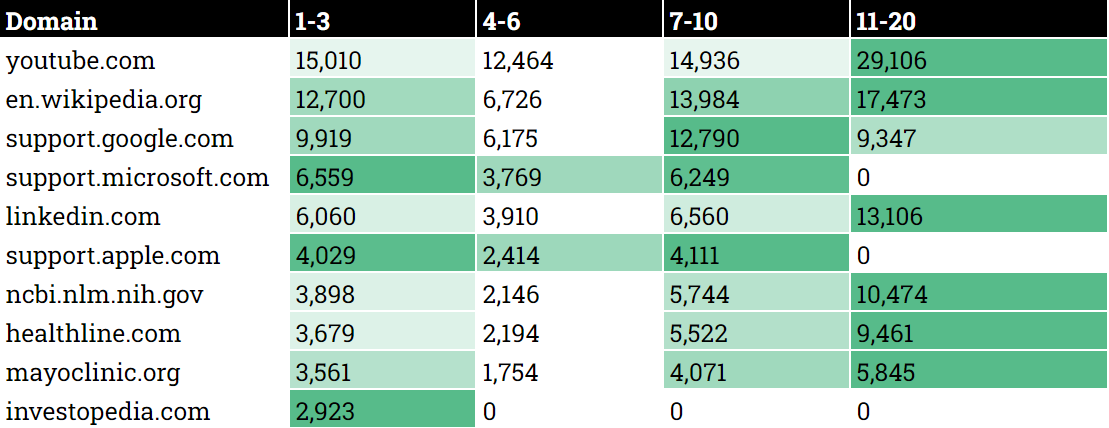 Где ранжируются 20 лучших доменов, которые видны в AIO и результатах поиска (Изображение предоставлено Кевином Индигом)
Где ранжируются 20 лучших доменов, которые видны в AIO и результатах поиска (Изображение предоставлено Кевином Индигом)Сценарии
Я буду работать со своими клиентами, чтобы соответствовать намерениям пользователя AIO, предоставлять уникальные идеи и адаптировать формат. Я вижу варианты для прогресса AI Overview, которые я буду отслеживать и подтверждать данными в ближайшие месяцы и годы.
Вариант 1: AIO больше полагаются на органические результаты с высоким рейтингом и удовлетворяют больше информационных намерений, прежде чем пользователям нужно будет перейти на веб-сайты. Большинство кликов, попадающих на сайты, будут от пользователей, которые рассматривают или намереваются купить.
Вариант 2: AIO продолжают предоставлять ответы из разнообразных результатов и оставляют небольшую вероятность того, что пользователи по-прежнему будут переходить к результатам с высоким рейтингом, хотя и в гораздо меньших количествах.
На какой сценарий вы делаете ставку?
Главное изображение: Пауло Бобита/Search Engine Journal
