
Google анонсировала замечательную структуру ранжирования под названием Term Weighting BERT (TW-BERT), которая улучшает результаты поиска и легко внедряется в существующие системы ранжирования.
Хотя Google не подтвердила, что использует TW-BERT, эта новая структура является прорывом, улучшающим процессы ранжирования по всем направлениям, в том числе при расширении запросов. Его также легко развернуть, что, на мой взгляд, повышает вероятность его использования.
У TW-BERT много соавторов, среди них Марк Найорквыдающийся научный сотрудник Google DeepMind и бывший старший директор по инженерным исследованиям в Google Research.
Он является соавтором многих исследовательских работ по темам, связанным с процессами ранжирования, и многим другим областям.
Среди статей Марк Найорк указан как соавтор:
- Об оптимизации показателей Top-K для моделей нейронного ранжирования — 2022 г.
- Динамические языковые модели для непрерывно развивающегося контента — 2021 г.
- Переосмысление поиска: из дилетантов сделать экспертов в предметной области — 2021
- Преобразование признаков для моделей нейронного ранжирования – – 2020
- Обучение ранжированию с помощью BERT в рейтинге TF — 2020
- Семантическое сопоставление текста для длинных документов — 2019
- TF-Ranking: масштабируемая библиотека TensorFlow для обучения рангу — 2018 г.
- Платформа LambdaLoss для оптимизации показателей ранжирования — 2018 г.
- Обучение ранжированию с предвзятостью выбора в личном поиске — 2016 г.
Содержание
Что такое ТВ-БЕРТ?
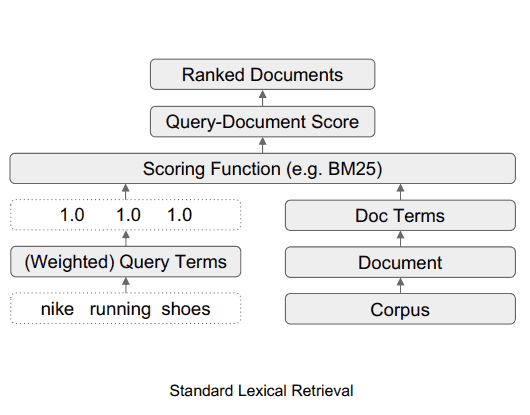
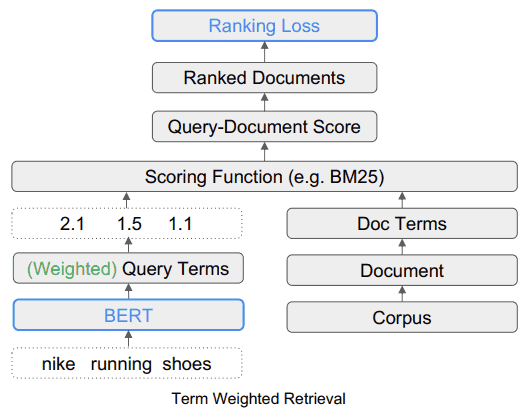
TW-BERT — это система ранжирования, которая присваивает баллы (называемые весовыми коэффициентами) словам в поисковом запросе, чтобы более точно определить, какие документы релевантны для этого поискового запроса.
TW-BERT также полезен при расширении запросов.
Расширение запроса — это процесс, который переформулирует поисковый запрос или добавляет к нему больше слов (например, добавление слова «рецепт» к запросу «куриный суп») для лучшего соответствия поискового запроса документам.
Добавление баллов к запросу помогает лучше определить, о чем идет речь.
TW-BERT объединяет две парадигмы поиска информации
В исследовательской работе обсуждаются два различных метода поиска. Один из них основан на статистике, а другой — на моделях глубокого обучения.
Далее следует обсуждение преимуществ и недостатков этих различных методов и предполагается, что TW-BERT — это способ объединить два подхода без каких-либо недостатков.
Они пишут:
«Эти методы поиска, основанные на статистике, обеспечивают эффективный поиск, который масштабируется по мере увеличения размера корпуса и обобщается на новые домены.
Однако термины взвешиваются независимо и не учитывают контекст всего запроса».
Затем исследователи отмечают, что модели глубокого обучения могут определять контекст поисковых запросов.
Это объясняется:
«Для этой проблемы модели глубокого обучения могут выполнять эту контекстуализацию по запросу, чтобы обеспечить лучшее представление для отдельных терминов».
Исследователи предлагают использовать TW-Bert для соединения двух методов.
Прорыв описан:
«Мы соединяем эти две парадигмы, чтобы определить, какие из них являются наиболее релевантными или нерелевантными поисковыми терминами в запросе…
Затем эти термины могут быть взвешены вверх или вниз, чтобы наша система поиска могла выдавать более релевантные результаты».
Пример взвешивания поискового термина TW-BERT
В исследовательской работе приводится пример поискового запроса «кроссовки Nike».
Проще говоря, слова «кроссовки Nike» — это три слова, которые алгоритм ранжирования должен понимать так, как хочет его понять пользователь.
Они объясняют, что выделение «бегущей» части запроса приведет к появлению нерелевантных результатов поиска, которые содержат бренды, отличные от Nike.
В этом примере важно название бренда Nike, и поэтому процесс ранжирования должен требовать, чтобы веб-страницы-кандидаты содержали слово Nike.
Веб-страницы-кандидаты — это страницы, которые рассматриваются в результатах поиска.
Что делает TW-BERT, так это предоставляет оценку (называемую взвешиванием) для каждой части поискового запроса, чтобы он имел смысл так же, как и человек, который ввел поисковый запрос.
В этом примере слово Nike считается важным, поэтому ему следует присвоить более высокий балл (взвешивание).
Исследователи пишут:
«Поэтому проблема заключается в том, что мы должны убедиться, что Nike» имеет достаточно высокий вес, но при этом предоставлять кроссовки в окончательных результатах».
Другая проблема заключается в том, чтобы затем понять контекст слов «бег» и «обувь», а это означает, что взвешивание должно быть выше для объединения двух слов в фразу «обувь для бега», вместо взвешивания двух слов по отдельности.
Эта проблема и решение объясняются:
«Второй аспект заключается в том, как использовать более значимые термины n-грамм во время подсчета очков.
В нашем запросе термины «бег» и «обувь» обрабатываются независимо, что может в равной степени соответствовать «носкам для бега» или «обуви для скейтбординга».
В этом случае мы хотим, чтобы наш ретривер работал на уровне терминов n-грамм, чтобы указать, что «кроссовки» должны быть взвешены при подсчете очков».
Устранение ограничений в текущих платформах
В исследовательской статье традиционное взвешивание обобщается как ограниченное вариантами запросов и упоминается, что эти методы взвешивания, основанные на статистике, менее эффективны для нулевых сценариев.
Zero-shot Learning — это ссылка на способность модели решать проблему, для которой она не была обучена.
Существует также краткое изложение ограничений, присущих современным методам расширения сроков.
Расширение термина — это когда синонимы используются для поиска большего количества ответов на поисковые запросы или когда выводится другое слово.
Например, когда кто-то ищет «куриный суп», предполагается, что это означает «куриный суп». рецепт».
О недостатках нынешних методов пишут:
«…эти вспомогательные функции оценки не учитывают дополнительные шаги взвешивания, выполняемые функциями оценки, используемыми в существующих средствах извлечения, такими как статистика запросов, статистика документов и значения гиперпараметров.
Это может изменить исходное распределение назначенных весов терминов во время окончательной оценки и поиска».
Далее исследователи заявляют, что у глубокого обучения есть свой багаж в виде сложности их развертывания и непредсказуемого поведения, когда они сталкиваются с новыми областями, для которых они не были предварительно обучены.
Именно здесь в игру вступает TW-BERT.
TW-BERT объединяет два подхода
Предлагаемое решение похоже на гибридный подход.
В следующей цитате термин IR означает поиск информации.
Они пишут:
«Чтобы восполнить пробел, мы используем надежность существующих лексических ретриверов с контекстуальными представлениями текста, обеспечиваемыми глубокими моделями.
Лексические ретриверы уже предоставляют возможность назначать веса запросам терминов n-грамм при выполнении поиска.
На этом этапе конвейера мы используем языковую модель, чтобы придать соответствующие веса терминам n-грамм запроса.
Этот BERT со взвешиванием терминов (TW-BERT) оптимизирован сквозным образом с использованием тех же функций оценки, которые используются в конвейере поиска, чтобы обеспечить согласованность между обучением и поиском.
Это приводит к улучшению поиска при использовании весов терминов, созданных TW-BERT, при сохранении инфраструктуры IR, аналогичной ее существующему производственному аналогу».
Алгоритм TW-BERT присваивает веса запросам, чтобы обеспечить более точную оценку релевантности, с которой затем может работать остальная часть процесса ранжирования.
Стандартный лексический поиск
Взвешенный поиск по срокам (TW-BERT)
TW-BERT прост в развертывании
Одним из преимуществ TW-BERT является то, что его можно вставить прямо в текущий процесс ранжирования поиска информации, как вставной компонент.
«Это позволяет нам напрямую использовать наши веса терминов в системе IR во время поиска.
Это отличается от предыдущих методов взвешивания, которые требуют дополнительной настройки параметров извлекателя для достижения оптимальной производительности поиска, поскольку они оптимизируют веса терминов, полученные с помощью эвристики, а не сквозную оптимизацию».
Что важно в этой простоте развертывания, так это то, что для добавления TW-BERT в процесс алгоритма ранжирования не требуется специализированного программного обеспечения или обновлений оборудования.
Использует ли Google TW-BERT в своем алгоритме ранжирования?
Как упоминалось ранее, развернуть TW-BERT относительно просто.
На мой взгляд, разумно предположить, что простота развертывания увеличивает вероятность того, что этот фреймворк можно будет добавить в алгоритм Google.
Это означает, что Google может добавить TW-BERT в ранжирующую часть алгоритма без необходимости выполнять полномасштабное обновление основного алгоритма.
Помимо простоты развертывания, еще одно качество, на которое следует обращать внимание при оценке того, можно ли использовать алгоритм, — это насколько успешно алгоритм улучшает текущее состояние дел.
Есть много исследовательских работ, которые имеют лишь ограниченный успех или не имеют никакого улучшения. Эти алгоритмы интересны, но разумно предположить, что они не войдут в алгоритм Google.
Интерес представляют те, которые очень успешны, и это случай с TW-BERT.
TW-BERT очень успешен. Они сказали, что его легко добавить в существующий алгоритм ранжирования, и что он работает так же хорошо, как «плотные нейронные ранкеры».
Исследователи объяснили, как это улучшает существующие системы ранжирования:
«Используя эти структуры извлечения, мы показываем, что наш метод взвешивания терминов превосходит базовые стратегии взвешивания терминов для задач в предметной области.
В задачах вне предметной области TW-BERT улучшает базовые стратегии взвешивания, а также плотные нейронные ранжировщики.
Далее мы показываем полезность нашей модели, интегрируя ее с существующими моделями расширения запросов, что повышает производительность по сравнению со стандартным поиском и плотным поиском в случаях нулевого выстрела.
Это мотивирует нас к тому, что наша работа может улучшить существующие поисковые системы с минимальными трудностями при адаптации».
Итак, это две веские причины, по которым TW-BERT уже может быть частью алгоритма ранжирования Google.
- Это повсеместное улучшение существующих рамок ранжирования.
- Его легко развернуть
Если Google развернул TW-BERT, то это может объяснить колебания рейтинга, о которых инструменты мониторинга SEO и члены сообщества поискового маркетинга сообщали в прошлом месяце.
Как правило, Google объявляет только о некоторых изменениях рейтинга, особенно когда они вызывают заметный эффект, например, когда Google объявил об алгоритме BERT.
В отсутствие официального подтверждения мы можем только предполагать, что TW-BERT является частью алгоритма поискового ранжирования Google.
Тем не менее, TW-BERT — замечательная структура, которая, по-видимому, повышает точность систем поиска информации и может быть использована Google.
Прочитайте оригинальную исследовательскую работу:
Сквозное взвешивание условий запроса (PDF)
Веб-страница исследования Google:
Сквозное взвешивание условий запроса
Избранное изображение Shutterstock/TPYXA Illustration
