
Барри Поллард из Google сделал длинное объяснение на Блюзский О том, почему Google Search Console говорит, что LCP плох, но отдельные URL -адреса в порядке. Я не хочу испортить это, поэтому я скопирую то, что написал Барри.
Вот что он написал в нескольких сообщениях на Блюзском:
Основная загадка веб -сайтов для вас:
Почему Google Search Console такая же, как мой LCP плох, но в каждом примере URL есть хороший LCP?
Я вижу разработчики спрашивает: как это может произойти? GSC неправ? (Я готов поспорить, что это не так!) Что вы можете с этим поделать?
Это по общему признанию сбивает с толку, так что давайте погрузимся в …
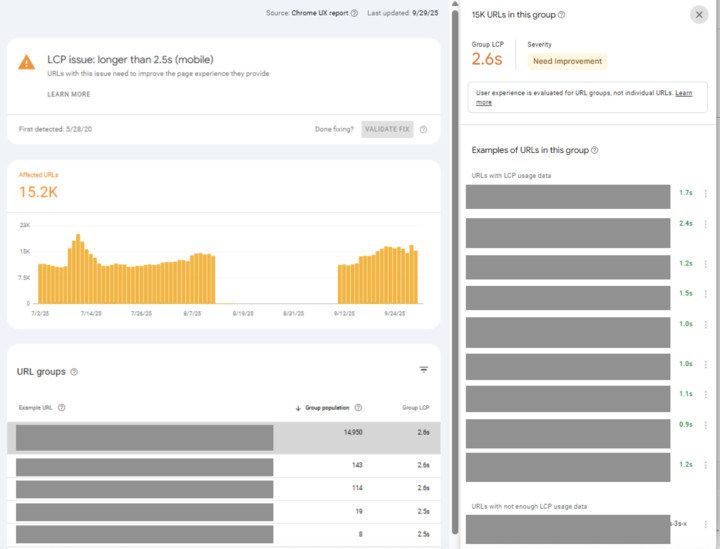
Во -первых, важно понять, как этот отчет и Crux измеряют основные веб -жизненные возможности, потому что, как только вы это сделаете, это более понятно, хотя все еще оставляет вопрос относительно того, что вы можете сделать с этим (мы доберемся до этого).
Проблема похожа на эту предыдущую ветку:
«Как для Круса можно сказать, что 90% загрузки страниц хороши, и консоль поиска Google сказать, что только 50% URL -адресов хороши. Что правильно?»
Это вопрос, который я задаю о основных вещах, и я признаю, что это сбивает с толку, но истина верна, потому что это разные меры …
1/5 🧵
— Барри Поллард (@tunetheweb.com) 19 августа 2025 года в 6:32
Страница Crux Sames Laters, а основной номер VITALS — это 75 -й процентиль этих страниц.
Это причудливый способ сказать: «Счет, который получает большинство просмотров страниц, — по крайней мере» — Whee «Большинство», составляет 75%.
Филипп Уолтон освещает его в этом видео:
https://www.youtube.com/watch?v=fWOI9DXMPDK
Для сайта электронной коммерции с большим количеством продуктов у вас будет очень популярные продукты (с множеством просмотров страниц!), А затем длинный, длинный хвост из многих, много менее популярных страниц (с небольшим количеством просмотров страниц).
Проблема возникает, когда длинный хвост составляет более 25% от общего объема просмотров страниц.
Популярные, скорее всего, будут иметь данные о сумасшедшем уровне (мы только при пересечении непубличного порога), поэтому из-за этого будут показаны в качестве примеров в GSC.
Это также те, на которых вы, вероятно, должны сосредоточиться — они получают трафик!
Но у популярных страниц есть еще один интересный предвзятость: они часто быстрее!
Почему? Потому что их часто кэшируют. В кэшах DB, в кэшах лака и особенно в узлах края CDN.
Длинные страницы хвоста гораздо чаще требуют полной нагрузки на страницу, пропуская все эти кеши, и поэтому будут медленнее.
Это верно, даже если страницы основаны на одной и той же технологии и оптимизируются одинаково с помощью всех тех же методов кодирования и оптимизированных изображений … и т. Д.
Кэши великолепны! Но они могут замаскировать медлительность, которую можно увидеть только для «промахи кеша».
И это часто, почему вы видите это в GSC.
Так как исправить?
Всегда будет предел размеров кэша, а кеши для замыкания для маленьких страниц не имеют большого смысла, поэтому вам необходимо сократить время нагрузки непотровую страницы.
Кэширование должно быть «вишней на вершине» для повышения скорости, а не единственной причиной, по которой у вас быстрый сайт.
Один из способов, которым мне нравится проверять это, — добавить случайный URL -параметр в URL (например, тест = 1234), а затем повторить тест маяка на его изменение значения каждый раз. Обычно это приводит к получению некрасивой страницы обратно.
Сравните это с запуск на кэшированной странице (запустив обычный URL пару раз).
Если это намного медленнее, то теперь вы понимаете разницу между вашим кэшированным и невыхарным и можете начать думать о способах улучшения этого.
В идеале вы получаете его менее 2,5 секунды, даже без кеша, и ваши (кэшированные) популярные страницы просто еще быстрее!
Между прочим, это также может быть тем, почему рекламные кампании (со случайными параматами UTM и тому подобное) также могут быть медленнее.
Вы можете настроить CDN, чтобы игнорировать их и не рассматривать их как к новым страницам. Есть также предстоящий стандарт, который позволяет странице указать, какие параметры не имеют значения:
Это круто и ждало, когда без различия в поисках исследований избегает правил спекуляций (с тех пор, где это было изначально началось) в более общий вариант использования.
Это позволяет вам сказать, что определенные URL-параметры на стороне клиента (например, GCLID или другие аналитические параметры) могут быть проигнорированы и по-прежнему использовать ресурс из кэша.
— Барри Поллард (@tunetheweb.com) 26 сентября 2025 года в 11:57
Обсуждение на форуме в БлюзскийПолем
