
Как вы знаете, Google обжаловала решение о монополии на поиск и подала в суд ряд новых документов. Одно из них — письменные показания Элизабет Рид, вице-президента и руководителя отдела поиска Google. Другой — Джесси Адкинс, директор по управлению продуктами для поискового синдикации и синдикации поисковых объявлений.
В Аффидевит Элизабет Рид — документ № 1471, Приложение № 2 Рид рассказывает о том, почему Google считает, что ей не следует прибегать к некоторым средствам судебной защиты.
В частности, Google не хочет соблюдать «Требуемое раскрытие данных» и раздел V под названием «Обязательное объединение результатов поиска». Почему? Рид написал: «Google понесет немедленный и непоправимый ущерб в результате передачи этой частной информации конкурентам Google, а также может понести непоправимый финансовый и репутационный ущерб в случае утечки или взлома данных, предоставленных конкурентам».
Подробности, которые Google должен будет предоставить конкурентам, включают:
- уникальный идентификатор («DocID») каждого документа (т. е. URL-адрес) в индексе веб-поиска Google и информацию, достаточную для выявления дубликатов;
- «сопоставление DocID с URL»; и
- «для каждого идентификатора документа: (A) время первого просмотра URL-адреса, (B) время последнего сканирования URL-адреса, (C) оценка спама и (D) флаг типа устройства».
Google считает, что передача этого позволит:
(1) Дать своим конкурентам несправедливое преимущество, потому что Google потратил десятки лет на разработку этих методов.
(2) Это выдаст, какие URL-адреса Google считает более важными, чем другие.
(3) Это позволит спамерам перепроектировать некоторые из его алгоритмов.
(4) Он сделает личную информацию поисковиков доступной своим конкурентам.
Гугл написал:
Во-первых, технология сканирования Google обрабатывает веб-страницы в открытой сети, полагаясь на собственные сигналы качества и свежести страниц, чтобы сосредоточиться на веб-страницах, которые с наибольшей вероятностью удовлетворят информационные потребности пользователей. Во-вторых, Google помечает просканированные веб-страницы собственными аннотациями для понимания страниц, включая сигналы для выявления спама и дубликатов страниц. Наконец, Google создает индекс, используя размеченные веб-страницы, созданные на этапе аннотаций. В индексе Google используется собственная многоуровневая структура, которая организует веб-страницы на основе того, как часто Google ожидает доступа к контенту и насколько свежим должен быть контент (чем свежее контент должен быть, тем чаще Google должен сканировать веб-страницу).
Далее он гласит: «Изображение ниже из демонстрационного примера (RDXD-28.005) показывает долю страниц (зеленого цвета), которые попадают в веб-индекс Google, по сравнению со страницами, которые Google сканирует (красным цветом). В соответствии с окончательным решением Google должен раскрыть Квалифицированным конкурентам курируемое подмножество, отмеченное зеленым цветом».
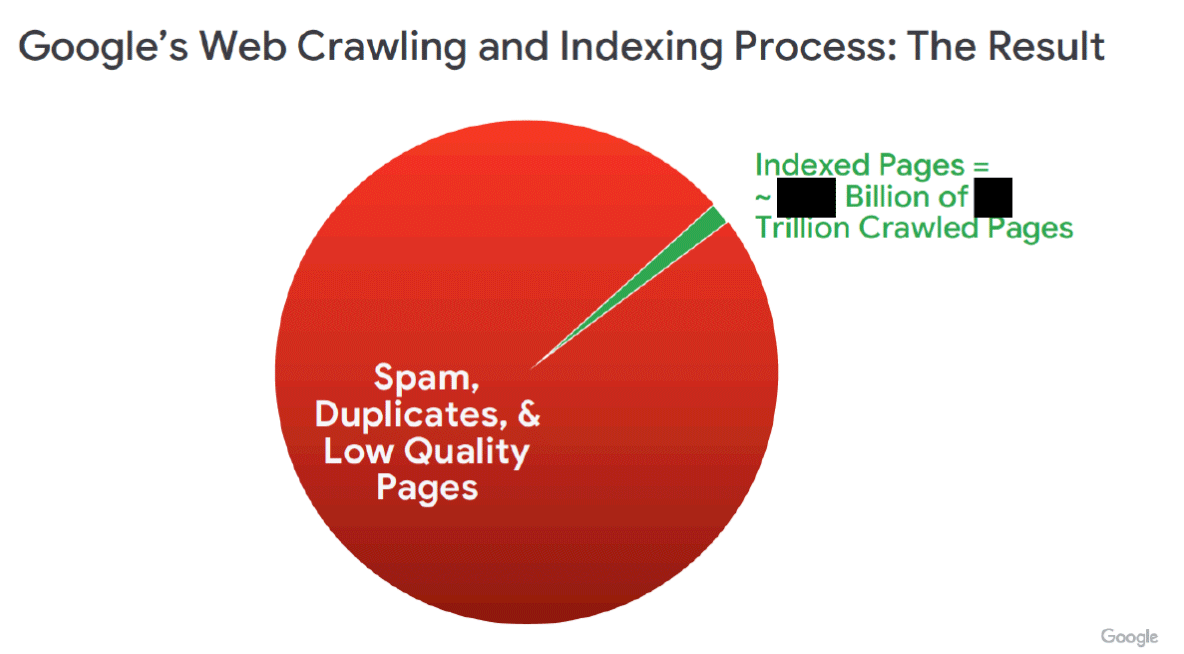
Да, это показывает, сколько URL-адресов Google знает о том, что индексируется Google. Это огромная разница!
Гугл добавил:
Если бы спамеры или другие злоумышленники получили доступ к спам-рейтингу Google от квалифицированных конкурентов посредством утечек или взломов данных (а это вполне реалистичный результат, учитывая огромную ценность данных), качество поиска Google ухудшится, а его пользователи подвергнутся увеличению количества спама, тем самым ослабив репутацию Google как надежной поисковой системы.
Раскрытие значений сигналов спама для проиндексированных веб-страниц Google посредством утечки или взлома данных ухудшит качество поиска Google и уменьшит способность Google обнаруживать спам. Как я свидетельствовал на слушаниях по делу о правовой защите, открытая сеть заполнена спамом. Google разработал обширные технологии борьбы со спамом, чтобы попытаться исключить спам из индекса. Борьба со спамом зависит от неясности, поскольку внешние знания о механизмах или сигналах борьбы со спамом сводят на нет ценность этих механизмов и сигналов.
Если спамеры или другие злоумышленники получат доступ к спам-рейтингу Google, они смогут обойти технологии обнаружения спама Google и помешать Google в ее усилиях по борьбе со спамом. Например, спамеры обычно покупают или взламывают законные веб-сайты и заменяют их содержимое спамом. Атака становится проще, если спамеры могут использовать спам-оценки Google для таргетинга на веб-страницы, которые Google оценил как низкий спам-риск. Таким образом, вынужденное раскрытие информации, скорее всего, приведет к появлению большего количества спама и вводящего в заблуждение контента в ответ на запросы пользователей, что поставит под угрозу безопасность пользователей и подорвет репутацию Google как надежной поисковой системы.
Затем он попадает в GLUE и RankEmbed:
Данные на стороне пользователя, используемые для построения, создания или эксплуатации статистической модели(-й) GLUE» и (ii) «Данные на стороне пользователя, используемые для обучения, построения или эксплуатации модели(-й) RankEmbed», «по предельной стоимости».
«Пользовательские данные», предусмотренные разделом IV.B Окончательного решения, включают в себя высокочувствительные пользовательские данные, включая, помимо прочего, запрос пользователя, местоположение, время поиска и то, как пользователь взаимодействовал с тем, что ему отображалось, например, при наведении курсора мыши и кликах.
Данные, используемые для построения модели Google «Glue», также включают все возвращаемые веб-результаты и их порядок, а также все возвращаемые функции поиска и их порядок. Модель Glue собирает эти данные журналов поиска за предыдущие тринадцать месяцев.
Вы также можете просмотреть Аффидевит Джесси Адкинса — документ № 1471, Приложение № 3. — это рекламная сторона.
Обсуждение на форуме Частные форумы Мари Хейнс (извините).
